JGroups and JBossCache provide the underlying communication, node replication and caching services, for JBoss AS clusters. Those services are configured as MBeans. There is a set of JBossCache and JGroups MBeans for each type of clustering applications (e.g., the Stateful Session EJBs, the distributed entity EJBs etc.).
The JBoss AS ships with a reasonable set of default JGroups and JBossCache MBean configurations. Most applications just work out of the box with the default MBean configurations. You only need to tweak them when you are deploying an application that has special network or performance requirements.
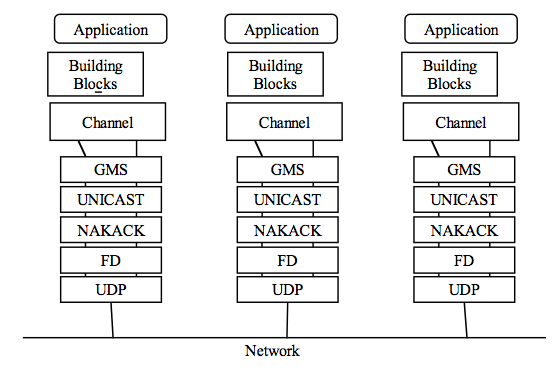
The JGroups framework provides services to enable peer-to-peer communications between nodes in a cluster. It is built on top a stack of network communication protocols that provide transport, discovery, reliability and failure detection, and cluster membership management services. Figure 17.1, “Protocol stack in JGroups” shows the protocol stack in JGroups.
JGroups configurations often appear as a nested attribute in cluster related MBean services, such as the PartitionConfig attribute in the ClusterPartition MBean or the ClusterConfig attribute in the TreeCache MBean. You can configure the behavior and properties of each protocol in JGroups via those MBean attributes. Below is an example JGroups configuration in the ClusterPartition MBean.
<mbean code="org.jboss.ha.framework.server.ClusterPartition"
name="jboss:service=DefaultPartition">
... ...
<attribute name="PartitionConfig">
<Config>
<UDP mcast_addr="228.1.2.3" mcast_port="45566"
ip_ttl="8" ip_mcast="true"
mcast_send_buf_size="800000" mcast_recv_buf_size="150000"
ucast_send_buf_size="800000" ucast_recv_buf_size="150000"
loopback="false"/>
<PING timeout="2000" num_initial_members="3"
up_thread="true" down_thread="true"/>
<MERGE2 min_interval="10000" max_interval="20000"/>
<FD shun="true" up_thread="true" down_thread="true"
timeout="2500" max_tries="5"/>
<VERIFY_SUSPECT timeout="3000" num_msgs="3"
up_thread="true" down_thread="true"/>
<pbcast.NAKACK gc_lag="50"
retransmit_timeout="300,600,1200,2400,4800"
max_xmit_size="8192"
up_thread="true" down_thread="true"/>
<UNICAST timeout="300,600,1200,2400,4800"
window_size="100" min_threshold="10"
down_thread="true"/>
<pbcast.STABLE desired_avg_gossip="20000"
up_thread="true" down_thread="true"/>
<FRAG frag_size="8192"
down_thread="true" up_thread="true"/>
<pbcast.GMS join_timeout="5000" join_retry_timeout="2000"
shun="true" print_local_addr="true"/>
<pbcast.STATE_TRANSFER up_thread="true" down_thread="true"/>
</Config>
</attribute>
</mbean>
All the JGroups configuration data is contained in the <Config> element under the JGroups config MBean attribute. In the next several sections, we will dig into the options in the <Config> element and explain exactly what they mean.
The transport protocols send messages from one cluster node to another (unicast) or from cluster node to all other nodes in the cluster (mcast). JGroups supports UDP, TCP, and TUNNEL as transport protocols.
Note
The UDP, TCP, and TUNNEL elements are mutually exclusive. You can only have one transport protocol in each JGroups Config element
UDP is the preferred protocol for JGroups. UDP uses multicast or multiple unicasts to send and receive messages. If you choose UDP as the transport protocol for your cluster service, you need to configure it in the UDP sub-element in the JGroups Config element. Here is an example.
<UDP mcast_send_buf_size="32000"
mcast_port="45566"
ucast_recv_buf_size="64000"
mcast_addr="228.8.8.8"
bind_to_all_interfaces="true"
loopback="true"
mcast_recv_buf_size="64000"
max_bundle_size="30000"
max_bundle_timeout="30"
use_incoming_packet_handler="false"
use_outgoing_packet_handler="false"
ucast_send_buf_size="32000"
ip_ttl="32"
enable_bundling="false"/>
The available attributes in the above JGroups configuration are listed below.
ip_mcast specifies whether or not to use IP multicasting. The default is true.
mcast_addr specifies the multicast address (class D) for joining a group (i.e., the cluster). The default is 228.8.8.8.
mcast_port specifies the multicast port number. The default is 45566.
bind_addr specifies the interface on which to receive and send multicasts (uses the bind.address system property, if present). If you have a multihomed machine, set the bind_addr attribute to the appropriate NIC IP address. Ignored if the ignore.bind.address property is true.
bind_to_all_interfaces specifies whether this node should listen on all interfaces for multicasts. The default is false. It overrides the bind_addr property for receiving multicasts. However, bind_addr (if set) is still used to send multicasts.
ip_ttl specifies the TTL for multicast packets.
use_incoming_packet_handler specifies whether to use a separate thread to process incoming messages.
use_outgoing_packet_handler specifies whether to use a separate thread to process outgoing messages.
enable_bundling specifies whether to enable bundling. If it is true, the node would queue outgoing messages until max_bundle_size bytes have accumulated, or max_bundle_time milliseconds have elapsed, whichever occurs first. Then bundle queued messages into a large message and send it. The messages are unbundled at the receiver. The default is false.
loopback specifies whether to loop outgoing message back up the stack. In unicast mode, the messages are sent to self. In mcast mode, a copy of the mcast message is sent.
discard_incompatibe_packets specifies whether to discard packets from different JGroups versions. Each message in the cluster is tagged with a JGroups version. When a message from a different version of JGroups is received, it will be discarded if set to true, otherwise a warning will be logged.
mcast_send_buf_size, mcast_recv_buf_size, ucast_send_buf_size, ucast_recv_buf_size define receive and send buffer sizes. It is good to have a large receiver buffer size, so packets are less likely to get dropped due to buffer overflow.
Note
On Windows 2000 machines, because of the media sense feature being broken with multicast (even after disabling media sense), you need to set the UDP protocol's loopback attribute to true.
Alternatively, a JGroups-based cluster can also work over TCP connections. Compared with UDP, TCP generates more network traffic when the cluster size increases but TCP is more reliable. TCP is fundamentally a unicast protocol. To send multicast messages, JGroups uses multiple TCP unicasts. To use TCP as a transport protocol, you should define a TCP element in the JGroups Config element. Here is an example of the TCP element.
<TCP start_port="7800"
bind_addr="192.168.5.1"
loopback="true"/>
Below are the attributes available in the TCP element.
bind_addr specifies the binding address. It can also be set with the -Dbind.address command line option at server startup.
start_port, end_port define the range of TCP ports the server should bind to. The server socket is bound to the first available port from start_port. If no available port is found (e.g., because of a firewall) before the end_port, the server throws an exception.
loopback specifies whether to loop outgoing message back up the stack. In unicast mode, the messages are sent to self. In mcast mode, a copy of the mcast message is sent.
mcast_send_buf_size, mcast_recv_buf_size, ucast_send_buf_size, ucast_recv_buf_size define receive and send buffer sizes. It is good to have a large receiver buffer size, so packets are less likely to get dropped due to buffer overflow.
conn_expire_time specifies the time (in milliseconds) after which a connection can be closed by the reaper if no traffic has been received.
reaper_interval specifies interval (in milliseconds) to run the reaper. If both values are 0, no reaping will be done. If either value is > 0, reaping will be enabled.
The TUNNEL protocol uses an external router to send messages. The external router is known as a GossipRouter. Each node has to register with the router. All messages are sent to the router and forwarded on to their destinations. The TUNNEL approach can be used to setup communication with nodes behind firewalls. A node can establish a TCP connection to the GossipRouter through the firewall (you can use port 80). The same connection is used by the router to send messages to nodes behind the firewall. The TUNNEL configuration is defined in the TUNNEL element in the JGroups Config element. Here is an example.
<TUNNEL router_port="12001"
router_host="192.168.5.1"/>
The available attributes in the TUNNEL element are listed below.
router_host specifies the host on which the GossipRouter is running.
router_port specifies the port on which the GossipRouter is listening.
loopback specifies whether to loop messages back up the stack. The default is true.
The cluster need to maintain a list of current member nodes at all times so that the load balancer and client interceptor know how to route their requests. The discovery protocols are used to discover active nodes in the cluster. All initial nodes are discovered when the cluster starts up. When a new node joins the cluster later, it is only discovered after the group membership protocol (GMS, see Section 17.1.5.1, “Group Membership”) admits it into the group.
Since the discovery protocols sit on top of the transport protocol. You can choose to use different discovery protocols based on your transport protocol. The discovery protocols are also configured as sub-elements in the JGroups MBean Config element.
The PING discovery protocol normally sits on top of the UDP transport protocol. Each node responds with a unicast UDP datagram back to the sender. Here is an example PING configuration under the JGroups Config element.
<PING timeout="2000"
num_initial_members="2"/>
The available attributes in the PING element are listed below.
timeout specifies the maximum number of milliseconds to wait for any responses.
num_initial_members specifies the maximum number of responses to wait for.
gossip_host specifies the host on which the GossipRouter is running.
gossip_port specifies the port on which the GossipRouter is listening on.
gossip_refresh specifies the interval (in milliseconds) for the lease from the GossipRouter.
initial_hosts is a comma-seperated list of addresses (e.g., host1[12345],host2[23456]), which are pinged for discovery.
If both gossip_host and gossip_port are defined, the cluster uses the GossipRouter for the initial discovery. If the initial_hosts is specified, the cluster pings that static list of addresses for discovery. Otherwise, the cluster uses IP multicasting for discovery.
Note
The discovery phase returns when the timeout ms have elapsed or the num_initial_members responses have been received.
The TCPGOSSIP protocol only works with a GossipRouter. It works essentially the same way as the PING protocol configuration with valid gossip_host and gossip_port attributes. It works on top of both UDP and TCP transport protocols. Here is an example.
<PING timeout="2000"
initial_hosts="192.168.5.1[12000],192.168.0.2[12000]"
num_initial_members="3"/>
The available attributes in the TCPGOSSIP element are listed below.
timeout specifies the maximum number of milliseconds to wait for any responses.
num_initial_members specifies the maximum number of responses to wait for.
initial_hosts is a comma-seperated list of addresses (e.g., host1[12345],host2[23456]) for GossipRouters to register with.
The TCPPING protocol takes a set of known members and ping them for discovery. This is essentially a static configuration. It works on top of TCP. Here is an example of the TCPPING configuration element in the JGroups Config element.
<TCPPING timeout="2000"
initial_hosts="192.168.5.1[7800],192.168.0.2[7800]"
port_range="2"
num_initial_members="3"/>
The available attributes in the TCPPING element are listed below.
timeout specifies the maximum number of milliseconds to wait for any responses.
num_initial_members specifies the maximum number of responses to wait for.
initial_hosts is a comma-seperated list of addresses (e.g., host1[12345],host2[23456]) for pinging.
port_range specifies the range of ports to ping on each host in the initial_hosts list. That is because multiple nodes can run on the same host. In the above example, the cluster would ping ports 7800, 7801, and 7802 on both hosts.
The MPING protocol is a multicast ping over TCP. It works almost the same way as PING works on UDP. It does not require external processes (GossipRouter) or static configuration (initial host list). Here is an example of the MPING configuration element in the JGroups Config element.
<MPING timeout="2000"
bind_to_all_interfaces="true"
mcast_addr="228.8.8.8"
mcast_port="7500"
ip_ttl="8"
num_initial_members="3"/>
The available attributes in the MPING element are listed below.
timeout specifies the maximum number of milliseconds to wait for any responses.
num_initial_members specifies the maximum number of responses to wait for.
bind_addr specifies the interface on which to send and receive multicast packets.
bind_to_all_interfaces overrides the bind_addr and uses all interfaces in multihome nodes.
mcast_addr, mcast_port, ip_ttl attributes are the same as related attributes in the UDP protocol configuration.
The failure detection protocols are used to detect failed nodes. Once a failed node is detected, the cluster updates its view so that the load balancer and client interceptors know to avoid the dead node. The failure detection protocols are configured as sub-elements in the JGroups MBean Config element.
The FD discovery protocol requires each node periodically sends are-you-alive messages to its neighbor. If the neighbor fails to respond, the calling node sends a SUSPECT message to the cluster. The current group coordinator double checks that the suspect node is indeed dead and updates the cluster's view. Here is an example FD configuration.
<FD timeout="2000"
max_tries="3"
shun="true"/>
The available attributes in the FD element are listed below.
timeout specifies the maximum number of milliseconds to wait for the responses to the are-you-alive messages.
max_tries specifies the number of missed are-you-alive messages from a node before the node is suspected.
shun specifies whether a failed node will be shunned. Once shunned, the node will be expelled from the cluster even if it comes back later. The shunned node would have to re-join the cluster through the discovery process.
Note
Regular traffic from a node counts as if it is a live. So, the are-you-alive messages are only sent when there is no regular traffic to the node for sometime.
The are-you-alive messages in the FD protocol could increase the network load when there are many nodes. It could also produce false suspicions. For instance, if the network is too busy and the timeout is too short, nodes could be falsely suspected. Also, if one node is suspended in a debugger or profiler, it could also be suspected and shunned. The FD_SOCK protocol addresses the above issues by suspecting node failures only when a regular TCP connection to the node fails. However, the problem with such passive detection is that hung nodes will not be detected until it is accessed and the TCP timeouts after several minutes. FD_SOCK works best in high load networks where all nodes are frequently accessed. The simplest FD_SOCK configuration does not take any attribute. You can just declare an empty FD_SOCK element in JGroups's Config element.
<FD_SOCK/>
There is only one optional attribute in the FD_SOCK element.
srv_sock_bind_addr specifies the interface to which the server socket should bind to. If it is omitted, the -D bind.address property from the server startup command line is used.
The FD_SIMPLE protocol is a more tolerant (less false suspicions) protocol based on are-you-alive messages. Each node periodically sends are-you-alive messages to a randomly choosen node and wait for a response. If a response has not been received within a certain timeout time, a counter associated with that node will be incremented. If the counter exceeds a certain value, that node will be suspected. When a response to an are-you-alive message is received, the counter resets to zero. Here is an example configuration for the FD_SIMPLE protocol.
<FD_SIMPLE timeout="2000"
max_missed_hbs="10"/>
The available attributes in the FD_SIMPLE element are listed below.
timeout specifies the timeout (in milliseconds) for the are-you-alive message. If a response is not received within timeout, the counter for the target node is increased.
max_missed_hbs specifies maximum number of are-you-alive messages (i.e., the counter value) a node can miss before it is suspected failure.
The reliable delivery protocols in the JGroups stack ensure that data pockets are actually delivered in the right order (FIFO) to the destination node. The basis for reliable message delivery is positive and negative delivery acknowledgments (ACK and NAK). In the ACK mode, the sender resends the message until the acknowledgment is received from the receiver. In the NAK mode, the receiver requests retransmission when it discovers a gap.
The UNICAST protocol is used for unicast messages. It uses ACK. It is configured as a sub-element under the JGroups Config element. Here is an example configuration for the UNICAST protocol.
<UNICAST timeout="100,200,400,800"/>
There is only one configurable attribute in the UNICAST element.
timeout specifies the retransmission timeout (in milliseconds). For instance, if the timeout is "100,200,400,800", the sender resends the message if it hasn't received an ACK after 100 ms the first time, and the second time it waits for 200 ms before resending, and so on.
The NAKACK protocol is used for multicast messages. It uses NAK. Under this protocol, each message is tagged with a sequence number. The receiver keeps track of the sequence numbers and deliver the messages in order. When a gap in the sequence number is detected, the receiver asks the sender to retransmit the missing message. The NAKACK protocol is configured as the pbcast.NAKACK sub-element under the JGroups Config element. Here is an example configuration.
<pbcast.NAKACK
max_xmit_size="8192"
use_mcast_xmit="true"
retransmit_timeout="600,1200,2400,4800"/>
The configurable attributes in the pbcast.NAKACK element are as follows.
retransmit_timeout specifies the retransmission timeout (in milliseconds). It is the same as the timeout attribute in the UNICAST protocol.
use_mcast_xmit determines whether the sender should send the retransmission to the entire cluster rather than just the node requesting it. This is useful when the sender drops the pocket -- so we do not need to retransmit for each node.
max_xmit_size specifies maximum size for a bundled retransmission, if multiple packets are reported missing.
discard_delivered_msgs specifies whether to discard delivery messages on the receiver nodes. By default, we save all delivered messages. However, if we only ask the sender to resend their messages, we can enable this option and discard delivered messages.
In addition to the protocol stacks, you can also configure JGroups network services in the Config element.
The group membership service in the JGroups stack maintains a list of active nodes. It handles the requests to join and leave the cluster. It also handles the SUSPECT messages sent by failure detection protocols. All nodes in the cluster, as well as the load balancer and client side interceptors, are notified if the group membership changes. The group membership service is configured in the pbcast.GMS sub-element under the JGroups Config element. Here is an example configuration.
<pbcast.GMS print_local_addr="true"
join_timeout="3000"
down_thread="false"
join_retry_timeout="2000"
shun="true"/>
The configurable attributes in the pbcast.GMS element are as follows.
join_timeout specifies the maximum number of milliseconds to wait for a new node JOIN request to succeed. Retry afterwards.
join_retry_timeout specifies the maximum number of milliseconds to wait after a failed JOIN to re-submit it.
print_local_addr specifies whether to dump the node's own address to the output when started.
shun specifies whether a node should shun itself if it receives a cluster view that it is not a member node.
disable_initial_coord specifies whether to prevent this node as the cluster coordinator.
The flow control service tries to adapt the sending data rate and the receiving data among nodes. If a sender node is too fast, it might overwhelm the receiver node and result in dropped packets that have to be retransmitted. In JGroups, the flow control is implemented via a credit-based system. The sender and receiver nodes have the same number of credits (bytes) to start with. The sender subtracts credits by the number of bytes in messages it sends. The receiver accumulates credits for the bytes in the messages it receives. When the sender's credit drops to a threshold, the receivers sends some credit to the sender. If the sender's credit is used up, the sender blocks until it receives credits from the receiver. The flow control service is configured in the FC sub-element under the JGroups Config element. Here is an example configuration.
<FC max_credits="1000000"
down_thread="false"
min_threshold="0.10"/>
The configurable attributes in the FC element are as follows.
max_credits specifies the maximum number of credits (in bytes). This value should be smaller than the JVM heap size.
min_credits specifies the threshold credit on the sender, below which the receiver should send in more credits.
min_threshold specifies percentage value of the threshold. It overrides the min_credits attribute.
The state transfer service transfers the state from an existing node (i.e., the cluster coordinator) to a newly joining node. It is configured in the pbcast.STATE_TRANSFER sub-element under the JGroups Config element. It does not have any configurable attribute. Here is an example configuration.
<pbcast.STATE_TRANSFER
down_thread="false"
up_thread="false"/>
In a JGroups cluster, all nodes have to store all messages received for potential retransmission in case of a failure. However, if we store all messages forever, we will run out of memory. So, the distributed garbage collection service in JGroups periodically purges messages that have seen by all nodes from the memory in each node. The distributed garbage collection service is configured in the pbcast.STABLE sub-element under the JGroups Config element. Here is an example configuration.
<pbcast.STABLE stability_delay="1000"
desired_avg_gossip="5000"
down_thread="false"
max_bytes="250000"/>
The configurable attributes in the pbcast.STABLE element are as follows.
desired_avg_gossip specifies intervals (in milliseconds) of garbage collection runs. Value 0 disables this service.
max_bytes specifies the maximum number of bytes received before the cluster triggers a garbage collection run. Value 0 disables this service.
max_gossip_runs specifies the maximum garbage collections runs before any changes. After this number is reached, there is no garbage collection until the message is received.
Note
Set the max_bytes attribute when you have a high traffic cluster.
When a network error occurs, the cluster might be partitioned into several different partitions. JGroups has a MERGE service that allows the coordinators in partitions to communicate with each other and form a single cluster back again. The flow control service is configured in the MERGE2 sub-element under the JGroups Config element. Here is an example configuration.
<MERGE2 max_interval="10000"
min_interval="2000"/>
The configurable attributes in the FC element are as follows.
max_interval specifies the maximum number of milliseconds to send out a MERGE message.
min_interval specifies the minimum number of milliseconds to send out a MERGE message.
JGroups chooses a random value between min_interval and max_interval to send out the MERGE message.
Note
The cluster states are not merged in a merger. This has to be done by the application.
JBoss Cache provides distributed cache and state replication services for the JBoss cluster. A JBoss cluster can have multiple JBoss Cache MBeans (known as the TreeCache MBean), one for HTTP session replication, one for stateful session beans, one for cached entity beans, etc. A generic TreeCache MBean configuration is listed below. Application specific TreeCache MBean configurations are covered in later chapters when those applications are discussed.
<mbean code="org.jboss.cache.TreeCache"
name="jboss.cache:service=TreeCache">
<depends>jboss:service=Naming</depends>
<depends>jboss:service=TransactionManager</depends>
<! -- Configure the TransactionManager -->
<attribute name="TransactionManagerLookupClass">
org.jboss.cache.DummyTransactionManagerLookup
</attribute>
<! --
Node locking level : SERIALIZABLE
REPEATABLE_READ (default)
READ_COMMITTED
READ_UNCOMMITTED
NONE
-->
<attribute name="IsolationLevel">REPEATABLE_READ</attribute>
<! -- Valid modes are LOCAL
REPL_ASYNC
REPL_SYNC
-->
<attribute name="CacheMode">LOCAL</attribute>
<! -- Name of cluster. Needs to be the same for all clusters, in order
to find each other -->
<attribute name="ClusterName">TreeCache-Cluster</attribute>
<! -- The max amount of time (in milliseconds) we wait until the
initial state (ie. the contents of the cache) are
retrieved from existing members in a clustered environment
-->
<attribute name="InitialStateRetrievalTimeout">5000</attribute>
<! -- Number of milliseconds to wait until all responses for a
synchronous call have been received.
-->
<attribute name="SyncReplTimeout">10000</attribute>
<! -- Max number of milliseconds to wait for a lock acquisition -->
<attribute name="LockAcquisitionTimeout">15000</attribute>
<! -- Name of the eviction policy class. -->
<attribute name="EvictionPolicyClass">
org.jboss.cache.eviction.LRUPolicy
</attribute>
<! -- Specific eviction policy configurations. This is LRU -->
<attribute name="EvictionPolicyConfig">
<config>
<attribute name="wakeUpIntervalSeconds">5</attribute>
<!-- Cache wide default -->
<region name="/_default_">
<attribute name="maxNodes">5000</attribute>
<attribute name="timeToLiveSeconds">1000</attribute>
</region>
<region name="/org/jboss/data">
<attribute name="maxNodes">5000</attribute>
<attribute name="timeToLiveSeconds">1000</attribute>
</region>
<region name="/org/jboss/test/data">
<attribute name="maxNodes">5</attribute>
<attribute name="timeToLiveSeconds">4</attribute>
</region>
</config>
</attribute>
<attribute name="CacheLoaderClass">
org.jboss.cache.loader.bdbje.BdbjeCacheLoader
</attribute>
<attribute name="CacheLoaderConfig">
location=c:\\tmp
</attribute>
<attribute name="CacheLoaderShared">true</attribute>
<attribute name="CacheLoaderPreload">
/a/b/c,/all/my/objects
</attribute>
<attribute name="CacheLoaderFetchTransientState">false</attribute>
<attribute name="CacheLoaderFetchPersistentState">true</attribute>
<attribute name="ClusterConfig">
... JGroups config for the cluster ...
</attribute>
</mbean>
The JGroups configuration element (i.e., the ClusterConfig attribute) is omitted from the above listing. You have learned how to configure JGroups earlier in this chapter (Section 17.1, “JGroups Configuration”). The TreeCache MBean takes the following attributes.
CacheLoaderClass specifies the fully qualified class name of the CacheLoader implementation.
CacheLoaderConfig contains a set of properties from which the specific CacheLoader implementation can configure itself.
CacheLoaderFetchPersistentState specifies whether to fetch the persistent state from another node. The persistence is fetched only if CacheLoaderShared is false. This attribute is only used if FetchStateOnStartup is true.
CacheLoaderFetchTransientState specifies whether to fetch the in-memory state from another node. This attribute is only used if FetchStateOnStartup is true.
CacheLoaderPreload contains a list of comma-separate nodes that need to be preloaded (e.g., /aop, /productcatalogue).
CacheLoaderShared specifies whether we want to shared a datastore, or whether each node wants to have its own local datastore.
CacheMode specifies how to synchronize cache between nodes. The possible values are LOCAL, REPL_SYNC, or REPL_ASYNC.
ClusterName specifies the name of the cluster. This value needs to be the same for all nodes in a cluster in order for them to find each other.
ClusterConfig contains the configuration of the underlying JGroups stack (see Section 17.1, “JGroups Configuration”.
EvictionPolicyClass specifies the name of a class implementing EvictionPolicy. You can use a JBoss Cache provided EvictionPolicy class or provide your own policy implementation. If this attribute is empty, no eviction policy is enabled.
EvictionPolicyConfig contains the configuration parameter for the specified eviction policy. Note that the content is provider specific.
FetchStateOnStartup specifies whether or not to acquire the initial state from existing members. It allows for warm/hot caches (true/false). This can be further defined by CacheLoaderFetchTransientState and CacheLoaderFetchPersistentState.
InitialStateRetrievalTimeout specifies the time in milliseconds to wait for initial state retrieval.
IsolationLevel specifies the node locking level. Possible values are SERIALIZABLE, REPEATABLE_READ (default), READ_COMMITTED, READ_UNCOMMITTED, and NONE.
LockAcquisitionTimeout specifies the time in milliseconds to wait for a lock to be acquired. If a lock cannot be acquired an exception will be thrown.
ReplQueueInterval specifies the time in milliseconds for elements from the replication queue to be replicated.
SyncReplTimeout specifies the time in milliseconds to wait until replication ACKs have been received from all nodes in the cluster. This attribute applies to synchronous replication mode only (i.e., CacheMode attribute is REPL_SYNC).
UseReplQueue specifies whether or not to use a replication queue (true/false). This attribute applies to synchronous replication mode only (i.e., CacheMode attribute is REPL_ASYNC).
ReplQueueMaxElements specifies the maximum number of elements in the replication queue until replication kicks in.
TransactionManagerLookupClass specifies the fully qualified name of a class implementing TransactionManagerLookup. The default is JBossTransactionManagerLookup for the transaction manager inside the JBoss AS. There is also an option of DummyTransactionManagerLookup for simple standalone examples.