This chapter will explore the use of container managed persistence (CMP) in JBoss. We will assume a basic familiarity the EJB CMP model and focus on the operation of the JBoss CMP engine. Specifically, we will look at how to configure and optimize CMP applications on JBoss. For more introductory coverage of basic CMP concepts, we recommend Enterprise Java Beans, Fourth Edition (O'Reilly 2004).
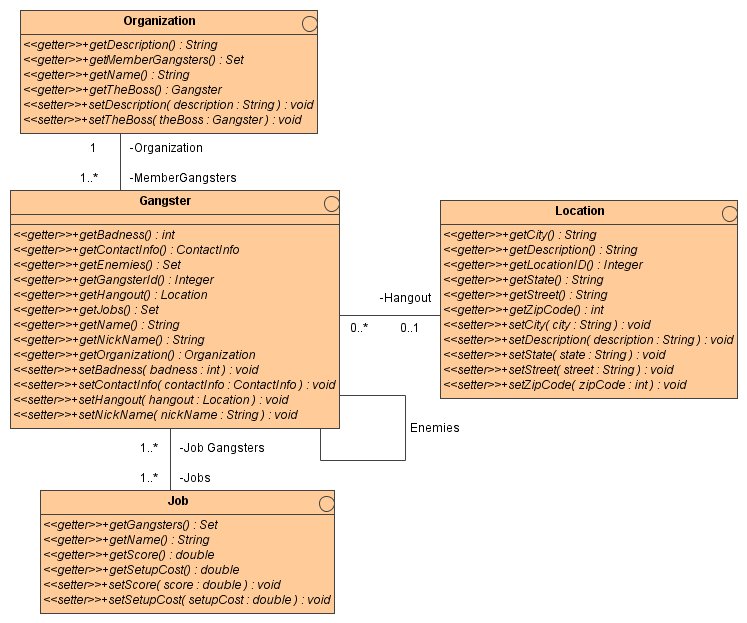
This chapter is example-driven. We will work with the crime portal application which stores information about imaginary criminal organizations. The data model we will be working with is shown in Figure 11.1, “The crime portal example classes”.
The source code for the crime portal is available in the src/main/org/jboss/cmp2 directory of the example code. To build the example code, run Ant as shown below
[examples]$ ant -Dchap=cmp2 config
This command builds and deploys the application to the JBoss server. When you start yours JBoss server, or if it is already running, you should see the following deployment messages:
15:46:36,704 INFO [OrganizationBean$Proxy] Creating organization Yakuza, Japanese Gangsters 15:46:36,790 INFO [OrganizationBean$Proxy] Creating organization Mafia, Italian Bad Guys 15:46:36,797 INFO [OrganizationBean$Proxy] Creating organization Triads, Kung Fu Movie Extras 15:46:36,877 INFO [GangsterBean$Proxy] Creating Gangster 0 'Bodyguard' Yojimbo 15:46:37,003 INFO [GangsterBean$Proxy] Creating Gangster 1 'Master' Takeshi 15:46:37,021 INFO [GangsterBean$Proxy] Creating Gangster 2 'Four finger' Yuriko 15:46:37,040 INFO [GangsterBean$Proxy] Creating Gangster 3 'Killer' Chow 15:46:37,106 INFO [GangsterBean$Proxy] Creating Gangster 4 'Lightning' Shogi 15:46:37,118 INFO [GangsterBean$Proxy] Creating Gangster 5 'Pizza-Face' Valentino 15:46:37,133 INFO [GangsterBean$Proxy] Creating Gangster 6 'Toohless' Toni 15:46:37,208 INFO [GangsterBean$Proxy] Creating Gangster 7 'Godfather' Corleone 15:46:37,238 INFO [JobBean$Proxy] Creating Job 10th Street Jeweler Heist 15:46:37,247 INFO [JobBean$Proxy] Creating Job The Greate Train Robbery 15:46:37,257 INFO [JobBean$Proxy] Creating Job Cheap Liquor Snatch and Grab
Since the beans in the examples are configured to have their tables removed on undeployment, anytime you restart the JBoss server you need to rerun the config target to reload the example data and re-deploy the application.
In order to get meaningful feedback from the chapter tests, you will want to increase the log level of the CMP subsystem before running running the test. To enable debug logging add the following category to your log4j.xml file:
<category name="org.jboss.ejb.plugins.cmp">
<priority value="DEBUG"/>
</category>In addition to this, it is necessary to decrease the threshold on the CONSOLE appender to allow debug level messages to be logged to the console. The following changes also need to be applied to the log4j.xml file.
<appender name="CONSOLE" class="org.apache.log4j.ConsoleAppender">
<errorHandler class="org.jboss.logging.util.OnlyOnceErrorHandler"/>
<param name="Target" value="System.out"/>
<param name="Threshold" value="DEBUG" />
<layout class="org.apache.log4j.PatternLayout">
<!-- The default pattern: Date Priority [Category] Message\n -->
<param name="ConversionPattern" value="%d{ABSOLUTE} %-5p [%c{1}] %m%n"/>
</layout>
</appender>To see the full workings of the CMP engine you would need to enable the custom TRACE level priority on the org.jboss.ejb.plugins.cmp category as shown here:
<category name="org.jboss.ejb.plugins.cmp">
<priority value="TRACE" class="org.jboss.logging.XLevel"/>
</category>The first test target illustrates a number of the customization features that will be discussed throughout this chapter. To run these tests execute the following ant target:
[examples]$ ant -Dchap=cmp2 -Dex=test run-example
22:30:09,862 DEBUG [OrganizationEJB#findByPrimaryKey] Executing SQL: SELECT t0_OrganizationEJ B.name FROM ORGANIZATION t0_OrganizationEJB WHERE t0_OrganizationEJB.name=? 22:30:09,927 DEBUG [OrganizationEJB] Executing SQL: SELECT desc, the_boss FROM ORGANIZATION W HERE (name=?) 22:30:09,931 DEBUG [OrganizationEJB] load relation SQL: SELECT id FROM GANGSTER WHERE (organi zation=?) 22:30:09,947 DEBUG [StatelessSessionContainer] Useless invocation of remove() for stateless s ession bean 22:30:10,086 DEBUG [GangsterEJB#findBadDudes_ejbql] Executing SQL: SELECT t0_g.id FROM GANGST ER t0_g WHERE (t0_g.badness > ?) 22:30:10,097 DEBUG [GangsterEJB#findByPrimaryKey] Executing SQL: SELECT t0_GangsterEJB.id FRO M GANGSTER t0_GangsterEJB WHERE t0_GangsterEJB.id=? 22:30:10,102 DEBUG [GangsterEJB#findByPrimaryKey] Executing SQL: SELECT t0_GangsterEJB.id FRO M GANGSTER t0_GangsterEJB WHERE t0_GangsterEJB.id=?
These tests exercise various finders, selectors and object to table mapping issues. We will refer to the tests throughout the chapter.
The other main target runs a set of tests to demonstrate the optimized loading configurations presented in Section 11.7, “Optimized Loading”. Now that the logging is setup correctly, the read-ahead tests will display useful information about the queries performed. Note that you do not have to restart the JBoss server for it to recognize the changes to the log4j.xml file, but it may take a minute or so. The following shows the actual execution of the readahead client:
[examples]$ ant -Dchap=cmp2 -Dex=readahead run-example
When the readahead client is executed, all of the SQL queries executed during the test are displayed in the JBoss server console. The important items of note when analyzing the output are the number of queries executed, the columns selected, and the number of rows loaded. The following shows the read-ahead none portion of the JBoss server console output from readahead:
22:44:31,570 INFO [ReadAheadTest] ######################################################## ### read-ahead none ### 22:44:31,582 DEBUG [GangsterEJB#findAll_none] Executing SQL: SELECT t0_g.id FROM GANGSTER t0_ g ORDER BY t0_g.id ASC 22:44:31,604 DEBUG [GangsterEJB] Executing SQL: SELECT name, nick_name, badness, organization , hangout FROM GANGSTER WHERE (id=?) 22:44:31,615 DEBUG [GangsterEJB] Executing SQL: SELECT name, nick_name, badness, organization , hangout FROM GANGSTER WHERE (id=?) 22:44:31,622 DEBUG [GangsterEJB] Executing SQL: SELECT name, nick_name, badness, organization , hangout FROM GANGSTER WHERE (id=?) 22:44:31,628 DEBUG [GangsterEJB] Executing SQL: SELECT name, nick_name, badness, organization , hangout FROM GANGSTER WHERE (id=?) 22:44:31,635 DEBUG [GangsterEJB] Executing SQL: SELECT name, nick_name, badness, organization , hangout FROM GANGSTER WHERE (id=?) 22:44:31,644 DEBUG [GangsterEJB] Executing SQL: SELECT name, nick_name, badness, organization , hangout FROM GANGSTER WHERE (id=?) 22:44:31,649 DEBUG [GangsterEJB] Executing SQL: SELECT name, nick_name, badness, organization , hangout FROM GANGSTER WHERE (id=?) 22:44:31,658 DEBUG [GangsterEJB] Executing SQL: SELECT name, nick_name, badness, organization , hangout FROM GANGSTER WHERE (id=?) 22:44:31,670 INFO [ReadAheadTest] ### ######################################################## ...
We will revisit this example and explore the output when we discuss the settings for optimized loading.
The jbosscmp-jdbc.xml descriptor is used to control the behavior of the JBoss engine. This can be done globally through the conf/standardjbosscmp-jdbc.xml descriptor found in the server configuration file set, or per EJB JAR deployment via a META-INF/jbosscmp-jdbc.xml descriptor.
The DTD for the jbosscmp-jdbc.xml descriptor can be found in JBOSS_DIST/docs/dtd/jbosscmp-jdbc_4_0.dtd. The public doctype for this DTD is:
<!DOCTYPE jbosscmp-jdbc PUBLIC
"-//JBoss//DTD JBOSSCMP-JDBC 4.0//EN"
"http://www.jboss.org/j2ee/dtd/jbosscmp-jdbc_4_0.dtd">The top level elements are shown in Figure 11.2, “The jbosscmp-jdbc content model.”.
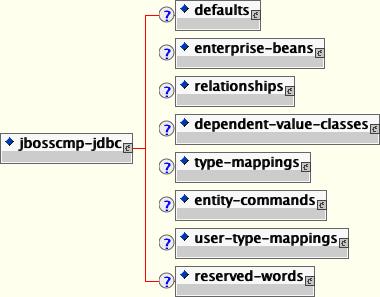
defaults: The defaults section allows for the specification of default behavior/settings for behavior that controls entity beans. Use of this section simplifies the amount of information needed for the common behaviors found in the entity beans section. See Section 11.12, “Defaults” for the details of the defaults content.
enterprise-beans: The enterprise-beans element allows for customization of entity beans defined in the ejb-jar.xml enterprise-beans descriptor. This is described in detail in Section 11.3, “Entity Beans”.
relationships: The relationships element allows for the customization of tables and the loading behavior of entity relationships. This is described in detail in Section 11.5, “Container Managed Relationships”.
dependent-value-classes: The dependent-value-classes element allows for the customization of the mapping of dependent value classes to tables. Dependent value classes are described in detail in Section 11.4.5, “Dependent Value Classes (DVCs)” (DVCs).
type-mappings: The type-mappings element defines the Java to SQL type mappings for a database, along with SQL templates, and function mappings. This is described in detail in Section 11.13, “Datasource Customization”.
entity-commands: The entity-commands element allows for the definition of the entity creation command instances that know how to create an entity instance in a persistent store. This is described in detail in Section 11.11, “Entity Commands and Primary Key Generation”.
user-type-mappings: The user-type-mappings elements defines a mapping of a user types to a column using a mapper class. A mapper is like a mediator. When storing, it takes an instance of the user type and translates it to a column value. When loading, it takes a column value and translates it to an instance of the user type. Details of the user type mappings are described in Section 11.13.4, “User Type Mappings”.
reserved-words: The reserved-words element defines one or more reserved words that should be escaped when generating tables. Each reserved word is specified as the content of a word element.
We'll start our look at entity beans in JBoss by examining one of the CMP entity beans in the crime portal. We'll look at the gangster bean, which is implemented as local CMP entity bean. Although JBoss can provide remote entity beans with pass-by-reference semantics for calls in the same VM to get the performance benefit as from local entity beans, the use of local entity beans is strongly encouraged.
We'll start with the required home interface. Since we're only concerned with the CMP fields at this point, we'll show only the methods dealing with the CMP fields.
// Gangster Local Home Interface
public interface GangsterHome
extends EJBLocalHome
{
Gangster create(Integer id, String name, String nickName)
throws CreateException;
Gangster findByPrimaryKey(Integer id)
throws FinderException;
}The local interface is what clients will use to talk. Again, it contains only the CMP field accessors.
// Gangster Local Interface
public interface Gangster
extends EJBLocalObject
{
Integer getGangsterId();
String getName();
String getNickName();
void setNickName(String nickName);
int getBadness();
void setBadness(int badness);
}Finally, we have the actual gangster bean. Despite it's size, very little code is actually required. The bulk of the class is the create method.
// Gangster Implementation Class
public abstract class GangsterBean
implements EntityBean
{
private EntityContext ctx;
private Category log = Category.getInstance(getClass());
public Integer ejbCreate(Integer id, String name, String nickName)
throws CreateException
{
log.info("Creating Gangster " + id + " '" + nickName + "' "+ name);
setGangsterId(id);
setName(name);
setNickName(nickName);
return null;
}
public void ejbPostCreate(Integer id, String name, String nickName) {
}
// CMP field accessors ---------------------------------------------
public abstract Integer getGangsterId();
public abstract void setGangsterId(Integer gangsterId);
public abstract String getName();
public abstract void setName(String name);
public abstract String getNickName();
public abstract void setNickName(String nickName);
public abstract int getBadness();
public abstract void setBadness(int badness);
public abstract ContactInfo getContactInfo();
public abstract void setContactInfo(ContactInfo contactInfo);
//...
// EJB callbacks ---------------------------------------------------
public void setEntityContext(EntityContext context) { ctx = context; }
public void unsetEntityContext() { ctx = null; }
public void ejbActivate() { }
public void ejbPassivate() { }
public void ejbRemove() { log.info("Removing " + getName()); }
public void ejbStore() { }
public void ejbLoad() { }
}The only thing missing now is the ejb-jar.xml deployment descriptor. Although the actual bean class is named GangsterBean, we've called the entity GangsterEJB.
<?xml version="1.0" encoding="UTF-8"?>
<ejb-jar xmlns="http://java.sun.com/xml/ns/j2ee" version="2.1"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee
http://java.sun.com/xml/ns/j2ee/ejb-jar_\2_1.xsd">
<display-name>Crime Portal</display-name>
<enterprise-beans>
<entity>
<display-name>Gangster Entity Bean</display-name>
<ejb-name>GangsterEJB</ejb-name>
<local-home>org.jboss.cmp2.crimeportal.GangsterHome</local-home>
<local>org.jboss.cmp2.crimeportal.Gangster</local>
<ejb-class>org.jboss.cmp2.crimeportal.GangsterBean</ejb-class>
<persistence-type>Container</persistence-type>
<prim-key-class>java.lang.Integer</prim-key-class>
<reentrant>False</reentrant>
<cmp-version>2.x</cmp-version>
<abstract-schema-name>gangster</abstract-schema-name>
<cmp-field>
<field-name>gangsterId</field-name>
</cmp-field>
<cmp-field>
<field-name>name</field-name>
</cmp-field>
<cmp-field>
<field-name>nickName</field-name>
</cmp-field>
<cmp-field>
<field-name>badness</field-name>
</cmp-field>
<cmp-field>
<field-name>contactInfo</field-name>
</cmp-field>
<primkey-field>gangsterId</primkey-field>
<!-- ... -->
</entity>
</enterprise-beans>
</ejb-jar>Note that we've specified a CMP version of 2.x to indicate that this is EJB 2.x CMP entity bean. The abstract schema name was set to gangster. That will be important when we look at EJB-QL queries in Section 11.6, “Queries”.
The JBoss configuration for the entity is declared with an entity element in the jbosscmp-jdbc.xml file. This file is located in the META-INF directory of the EJB JAR and contains all of the optional configuration information for configuring the CMP mapping. The entity elements for each entity bean are grouped together in the enterprise-beans element under the top level jbosscmp-jdbc element. A stubbed out entity configuration is shown below.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE jbosscmp-jdbc PUBLIC
"-//JBoss//DTD JBOSSCMP-JDBC 3.2//EN"
"http://www.jboss.org/j2ee/dtd/jbosscmp-jdbc_3_2.dtd">
<jbosscmp-jdbc>
<defaults>
<!-- application-wide CMP defaults -->
</defaults>
<enterprise-beans>
<entity>
<ejb-name>GangsterEJB</ejb-name>
<!-- overrides to defaults section -->
<table-name>gangster</table-name>
<!-- CMP Fields (see CMP-Fields) -->
<!-- Load Groups (see Load Groups)-->
<!-- Queries (see Queries) -->
</entity>
</enterprise-beans>
</jbosscmp-jdbc>The ejb-name element is required to match the entity specification here with the one in the ejb-jar.xml file. The remainder of the elements specify either overrides the global or application-wide CMP defaults and CMP mapping details specific to the bean. The application defaults come from the defaults section of the jbosscmp-jdbc.xml file and the global defaults come from the defaults section of the standardjbosscmp-jdbc.xml file in the conf directory for the current server configuration file set. The defaults section is discussed in Section 11.12, “Defaults”. Figure 11.3, “The entity element content model ” shows the full entity content model.
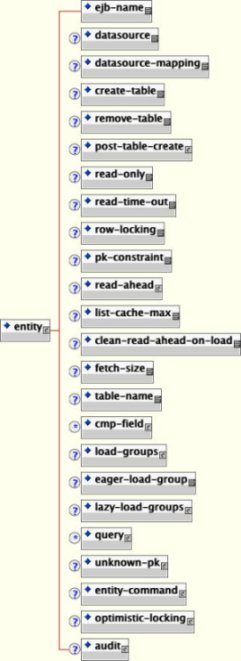
A detailed description of each entity element follows:
ejb-name: This required element is the name of the EJB to which this configuration applies. This element must match an ejb-name of an entity in the ejb-jar.xml file.
datasource: This optional element is the jndi-name used to look up the datasource. All database connections used by an entity or relation-table are obtained from the datasource. Having different datasources for entities is not recommended, as it vastly constrains the domain over which finders and ejbSelects can query. The default is java:/DefaultDS unless overridden in the defaults section.
datasource-mapping: This optional element specifies the name of the type-mapping, which determines how Java types are mapped to SQL types, and how EJB-QL functions are mapped to database specific functions. Type mappings are discussed in Section 11.13.3, “Mapping”. The default is Hypersonic SQL unless overridden in the defaults section.
create-table: This optional element when true, specifies that JBoss should attempt to create a table for the entity. When the application is deployed, JBoss checks if a table already exists before creating the table. If a table is found, it is logged, and the table is not created. This option is very useful during the early stages of development when the table structure changes often. The default is false unless overridden in the defaults section.
alter-table: If create-table is used to automatically create the schema, alter-table can be used to keep the schema current with changes to the entity bean. Alter table will perform the following specific tasks:
new fields will be created
fields which are no longer used will be removed
string fields which are shorter than the declared length will have their length increased to the declared length. (not supported by all databases)
remove-table: This optional element when true, JBoss will attempt to drop the table for each entity and each relation table mapped relationship. When the application is undeployed, JBoss will attempt to drop the table. This option is very useful during the early stages of development when the table structure changes often. The default is false unless overridden in the defaults section.
post-table-create: This optional element specifies an arbitrary SQL statement that should be executed immediately after the database table is created. This command is only executed if create-table is true and the table did not previously exist.
read-only: This optional element when true specifies that the bean provider will not be allowed to change the value of any fields. A field that is read-only will not be stored in, or inserted into, the database. If a primary key field is read-only, the create method will throw a CreateException. If a set accessor is called on a read-only field, it throws an EJBException. Read-only fields are useful for fields that are filled in by database triggers, such as last update. The read-only option can be overridden on a per cmp-field basis, and is discussed in Section 11.4.3, “Read-only Fields”. The default is false unless overridden in the defaults section.
read-time-out: This optional element is the amount of time in milliseconds that a read on a read-only field is valid. A value of 0 means that the value is always reloaded at the start of a transaction, and a value of -1 means that the value never times out. This option can also be overridden on a per cmp-field basis. If read-only is false, this value is ignored. The default is -1 unless overridden in the defaults section.
row-locking: This optional element if true specifies that JBoss will lock all rows loaded in a transaction. Most databases implement this by using the SELECT FOR UPDATE syntax when loading the entity, but the actual syntax is determined by the row-locking-template in the datasource-mapping used by this entity. The default is false unless overridden in the defaults section.
pk-constraint: This optional element if true specifies that JBoss will add a primary key constraint when creating tables. The default is true unless overridden in the defaults section.
read-ahead: This optional element controls caching of query results and cmr-fields for the entity. This option is discussed in Section 11.7.3, “Read-ahead”.
fetch-size: This optional element specifies the number of entities to read in one round-trip to the underlying datastore. The default is 0 unless overridden in the defaults section.
list-cache-max: This optional element specifies the number of read-lists that can be tracked by this entity. This option is discussed in on-load. The default is 1000 unless overridden in the defaults section.
clean-read-ahead-on-load: When an entity is loaded from the read ahead cache, JBoss can remove the data used from the read ahead cache. The default is false.
table-name: This optional element is the name of the table that will hold data for this entity. Each entity instance will be stored in one row of this table. The default is the ejb-name.
cmp-field: The optional element allows one to define how the ejb-jar.xml cmp-field is mapped onto the persistence store. This is discussed in Section 11.4, “CMP Fields”.
load-groups: This optional element specifies one or more groupings of CMP fields to declare load groupings of fields. This is discussed in Section 11.7.2, “Load Groups”.
eager-load-groups: This optional element defines one or more load grouping as eager load groups. This is discussed in Section 11.8.2, “Eager-loading Process”.
lazy-load-groups: This optional element defines one or more load grouping as lazy load groups. This is discussed in Section 11.8.3, “Lazy loading Process”.
query: This optional element specifies the definition of finders and selectors. This is discussed in Section 11.6, “Queries”.
unknown-pk: This optional element allows one to define how an unknown primary key type of java.lang.Object maps to the persistent store.
entity-command: This optional element allows one to define the entity creation command instance. Typically this is used to define a custom command instance to allow for primary key generation. This is described in detail in Section 11.11, “Entity Commands and Primary Key Generation”.
optimistic-locking: This optional element defines the strategy to use for optimistic locking. This is described in detail in Section 11.10, “Optimistic Locking”.
audit: This optional element defines the CMP fields that will be audited. This is described in detail in Section 11.4.4, “Auditing Entity Access”.
CMP fields are declared on the bean class as abstract getter and setter methods that follow the JavaBean property accessor conventions. Our gangster bean, for example, has a getName() and a setName() method for accessing the name CMP field. In this section we will look at how the configure these declared CMP fields and control the persistence and behavior.
The declaration of a CMP field starts in the ejb-jar.xml file. On the gangster bean, for example, the gangsterId, name, nickName and badness would be declared in the ejb-jar.xml file as follows:
<ejb-jar>
<enterprise-beans>
<entity>
<ejb-name>GangsterEJB</ejb-name>
<cmp-field><field-name>gangsterId</field-name></cmp-field>
<cmp-field><field-name>name</field-name></cmp-field>
<cmp-field><field-name>nickName</field-name></cmp-field>
<cmp-field><field-name>badness</field-name></cmp-field>
</entity>
</enterprise-beans>
</ejb-jar>Note that the J2EE deployment descriptor doesn't declare any object-relational mapping details or other configuration. It is nothing more than a simple declaration of the CMP fields.
The relational mapping configuration of a CMP field is done in the jbosscmp-jdbc.xml file. The structure is similar to the ejb-jar.xml with an entity element that has cmp-field elements under it with the additional configuration details.
The following is shows the basic column name and data type mappings for the gangster bean.
<jbosscmp-jdbc>
<enterprise-beans>
<entity>
<ejb-name>GangsterEJB</ejb-name>
<table-name>gangster</table-name>
<cmp-field>
<field-name>gangsterId</field-name>
<column-name>id</column-name>
</cmp-field>
<cmp-field>
<field-name>name</field-name>
<column-name>name</column-name>
<not-null/>
</cmp-field>
<cmp-field>
<field-name>nickName</field-name>
<column-name>nick_name</column-name>
<jdbc-type>VARCHAR</jdbc-type>
<sql-type>VARCHAR(64)</sql-type>
</cmp-field>
<cmp-field>
<field-name>badness</field-name>
<column-name>badness</column-name>
</cmp-field>
</entity>
</enterprise-beans>
</jbosscmp-jdbc>The full content model of the cmp-field element of the jbosscmp-jdbc.xml is shown below.
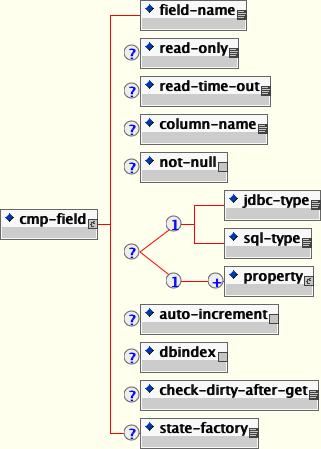
A detailed description of each element follows:
field-name: This required element is the name of the cmp-field that is being configured. It must match the field-name element of a cmp-field declared for this entity in the ejb-jar.xml file.
read-only: This declares that field in question is read-only. This field will not be written to the database by JBoss. Read-only fields are discussed in Section 11.4.3, “Read-only Fields”.
read-only-timeout: This is the time in milliseconds that a read-only field value will be considered valid.
column-name: This optional element is the name of the column to which the cmp-field is mapped. The default is to use the field-name value.
not-null: This optional element indicates that JBoss should add a NOT NULL to the end of the column declaration when automatically creating the table for this entity. The default for primary key fields and primitives is not null.
jdbc-type: This is the JDBC type that is used when setting parameters in a JDBC prepared statement or loading data from a JDBC result set. The valid types are defined in java.sql.Types. This is only required if sql-type is specified. The default JDBC type will be based on the database type in the datasourcemapping.
sql-type: This is the SQL type that is used in create table statements for this field. Valid SQL types are only limited by your database vendor. This is only required if jdbc-type is specified. The default SQL type will be base on the database type in the datasourcemapping
property: This optional element allows one to define how the properties of a dependent value class CMP field should be mapped to the persistent store. This is discussed further in Section 11.4.5, “Dependent Value Classes (DVCs)”.
auto-increment: The presence of this optional field indicates that it is automatically incremented by the database layer. This is used to map a field to a generated column as well as to an externally manipulated column.
dbindex: The presence of this optional field indicates that the server should create an index on the corresponding column in the database. The index name will be fieldname_index.
check-dirty-after-get: This value defaults to false for primitive types and the basic java.lang immutable wrappers (Integer, String, etc...). For potentially mutable objects, JBoss will mark they field as potentially dirty after a get operation. If the dirty check on an object is too expensive, you can optimize it away by setting check-dirty-after-get to false.
state-factory: This specifies class name of a state factory object which can perform dirty checking for this field. State factory classes must implement the CMPFieldStateFactory interface.
JBoss allows for read-only CMP fields by setting the read-only and read-time-out elements in the cmp-field declaration. These elements work the same way as they do at the entity level. If a field is read-only, it will never be used in an INSERT or UPDATE statement. If a primary key field is read-only, the create method will throw a CreateException. If a set accessor is called for a read-only field, it throws an EJBException. Read-only fields are useful for fields that are filled in by database triggers, such as last update. A read-only CMP field declaration example follows:
<jbosscmp-jdbc>
<enterprise-beans>
<entity>
<ejb-name>GangsterEJB</ejb-name>
<cmp-field>
<field-name>lastUpdated</field-name>
<read-only>true</read-only>
<read-time-out>1000</read-time-out>
</cmp-field>
</entity>
</enterprise-beans>
</jbosscmp-jdbc>The audit element of the entity section allows one to specify how access to and entity bean is audited. This is only allowed when an entity bean is accessed under a security domain so that this is a caller identity established. The content model of the audit element is given Figure 11.5, “The jbosscmp-jdbc.xml audit element content model ”.
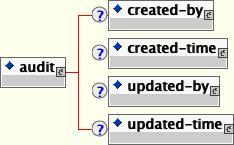
created-by: This optional element indicates that the caller who created the entity should be saved to either the indicated column-name or cmp field-name.
created-time: This optional element indicates that the time of entity creation should be saved to either the indicated column-name or cmp field-name.
updated-by: This optional element indicates that the caller who last modified the entity should be saved to either the indicated column-name or CMP field-name.
updated-time: This optional element indicates that the last time of entity modification should be saved to either the indicated column-name or CMP field-name.
For each element, if a field-name is given, the corresponding audit information should be stored in the specified CMP field of the entity bean being accessed. Note that there does not have to be an corresponding CMP field declared on the entity. In case there are matching field names, you will be able to access audit fields in the application using the corresponding CMP field abstract getters and setters. Otherwise, the audit fields will be created and added to the entity internally. You will be able to access audit information in EJB-QL queries using the audit field names, but not directly through the entity accessors.
If, on the other hand, a column-name is specified, the corresponding audit information should be stored in the indicated column of the entity table. If JBoss is creating the table the jdbc-type and sql-type element can then be used to define the storage type.
The declaration of audit information with given column names is shown below.
<jbosscmp-jdbc>
<enterprise-beans>
<entity>
<ejb-name>AuditChangedNamesEJB</ejb-name>
<table-name>cmp2_audit_changednames</table-name>
<audit>
<created-by>
<column-name>createdby</column-name>
</created-by>
<created-time>
<column-name>createdtime</column-name>
</created-time>
<updated-by>
<column-name>updatedby</column-name></updated-by>
<updated-time>
<column-name>updatedtime</column-name>
</updated-time>
</audit>
</entity>
</enterprise-beans>
</jbosscmp-jdbc>A dependent value class (DVC) is a fancy term used to identity any Java class that is the type of a cmp-field other than the automatically recognized types core types such as strings and number values. By default, a DVC is serialized, and the serialized form is stored in a single database column. Although not discussed here, there are several known issues with the long-term storage of classes in serialized form.
JBoss also supports the storage of the internal data of a DVC into one or more columns. This is useful for supporting legacy JavaBeans and database structures. It is not uncommon to find a database with a highly flattened structure (e.g., a PURCHASE_ORDER table with the fields SHIP_LINE1, SHIP_LINE2, SHIP_CITY, etc. and an additional set of fields for the billing address). Other common database structures include telephone numbers with separate fields for area code, exchange, and extension, or a person's name spread across several fields. With a DVC, multiple columns can be mapped to one logical field.
JBoss requires that a DVC to be mapped must follow the JavaBeans naming specification for simple properties, and that each property to be stored in the database must have both a getter and a setter method. Furthermore, the bean must be serializable and must have a no argument constructor. A property can be any simple type, an unmapped DVC or a mapped DVC, but cannot be an EJB. A DVC mapping is specified in a dependent-value-class element within the dependent-value-classes element.
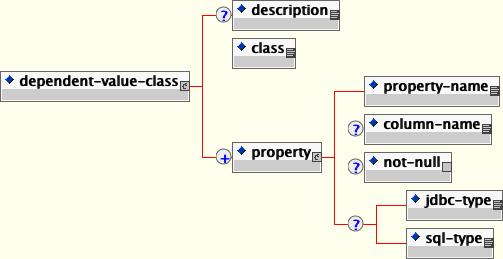
Here is an example of a simple ContactInfo DVC class.
public class ContactInfo
implements Serializable
{
/** The cell phone number. */
private PhoneNumber cell;
/** The pager number. */
private PhoneNumber pager;
/** The email address */
private String email;
/**
* Creates empty contact info.
*/
public ContactInfo() {
}
public PhoneNumber getCell() {
return cell;
}
public void setCell(PhoneNumber cell) {
this.cell = cell;
}
public PhoneNumber getPager() {
return pager;
}
public void setPager(PhoneNumber pager) {
this.pager = pager;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email.toLowerCase();
}
// ... equals, hashCode, toString
}The contact info includes a phone number, which is represented by another DVC class.
public class PhoneNumber
implements Serializable
{
/** The first three digits of the phone number. */
private short areaCode;
/** The middle three digits of the phone number. */
private short exchange;
/** The last four digits of the phone number. */
private short extension;
// ... getters and setters
// ... equals, hashCode, toString
} The DVC mappings for these two classes are relatively straight forward.
<dependent-value-classes>
<dependent-value-class>
<description>A phone number</description>
<class>org.jboss.cmp2.crimeportal.PhoneNumber</class>
<property>
<property-name>areaCode</property-name>
<column-name>area_code</column-name>
</property>
<property>
<property-name>exchange</property-name>
<column-name>exchange</column-name>
</property>
<property>
<property-name>extension</property-name>
<column-name>extension</column-name>
</property>
</dependent-value-class>
<dependent-value-class>
<description>General contact info</description>
<class>org.jboss.cmp2.crimeportal.ContactInfo</class>
<property>
<property-name>cell</property-name>
<column-name>cell</column-name>
</property>
<property>
<property-name>pager</property-name>
<column-name>pager</column-name>
</property>
<property>
<property-name>email</property-name>
<column-name>email</column-name>
<jdbc-type>VARCHAR</jdbc-type>
<sql-type>VARCHAR(128)</sql-type>
</property>
</dependent-value-class>
</dependent-value-classes>Each DVC is declared with a dependent-value-class element. A DVC is identified by the Java class type declared in the class element. Each property to be persisted is declared with a property element. This specification is based on the cmp-field element, so it should be self-explanatory. This restriction will also be removed in a future release. The current proposal involves storing the primary key fields in the case of a local entity and the entity handle in the case of a remote entity.
The dependent-value-classes section defines the internal structure and default mapping of the classes. When JBoss encounters a field that has an unknown type, it searches the list of registered DVCs, and if a DVC is found, it persists this field into a set of columns, otherwise the field is stored in serialized form in a single column. JBoss does not support inheritance of DVCs; therefore, this search is only based on the declared type of the field. A DVC can be constructed from other DVCs, so when JBoss runs into a DVC, it flattens the DVC tree structure into a set of columns. If JBoss finds a DVC circuit during startup, it will throw an EJBException. The default column name of a property is the column name of the base cmp-field followed by an underscore and then the column name of the property. If the property is a DVC, the process is repeated. For example, a cmp-field named info that uses the ContactInfo DVC would have the following columns:
info_cell_area_code info_cell_exchange info_cell_extension info_pager_area_code info_pager_exchange info_pager_extension info_email
The automatically generated column names can quickly become excessively long and awkward. The default mappings of columns can be overridden in the entity element as follows:
<jbosscmp-jdbc>
<enterprise-beans>
<entity>
<ejb-name>GangsterEJB</ejb-name>
<cmp-field>
<field-name>contactInfo</field-name>
<property>
<property-name>cell.areaCode</property-name>
<column-name>cell_area</column-name>
</property>
<property>
<property-name>cell.exchange</property-name>
<column-name>cell_exch</column-name>
</property>
<property>
<property-name>cell.extension</property-name>
<column-name>cell_ext</column-name>
</property>
<property>
<property-name>pager.areaCode</property-name>
<column-name>page_area</column-name>
</property>
<property>
<property-name>pager.exchange</property-name>
<column-name>page_exch</column-name>
</property>
<property>
<property-name>pager.extension</property-name>
<column-name>page_ext</column-name>
</property>
<property>
<property-name>email</property-name>
<column-name>email</column-name>
<jdbc-type>VARCHAR</jdbc-type>
<sql-type>VARCHAR(128)</sql-type>
</property>
</cmp-field>
</entity>
</enterprise-beans>
</jbosscmp-jdbc>When overriding property info for the entity, you need to refer to the property from a flat perspective as in cell.areaCode.
Container Managed Relationships (CMRs) are a powerful new feature of CMP 2.0. Programmers have been creating relationships between entity objects since EJB 1.0 was introduced (not to mention since the introduction of databases), but before CMP 2.0 the programmer had to write a lot of code for each relationship in order to extract the primary key of the related entity and store it in a pseudo foreign key field. The simplest relationships were tedious to code, and complex relationships with referential integrity required many hours to code. With CMP 2.0 there is no need to code relationships by hand. The container can manage one-to-one, one-to-many and many-to-many relationships, with referential integrity. One restriction with CMRs is that they are only defined between local interfaces. This means that a relationship cannot be created between two entities in separate applications, even in the same application server.
There are two basic steps to create a container managed relationship: create the cmr-field abstract accessors and declare the relationship in the ejb-jar.xml file. The following two sections describe these steps.
CMR-Field abstract accessors have the same signatures as cmp-fields, except that single-valued relationships must return the local interface of the related entity, and multi-valued relationships can only return a java.util.Collection (or java.util.Set) object. For example, to declare a one-to-many relationship between organization and gangster, we declare the relationship from organization to gangster in the OrganizationBean class:
public abstract class OrganizationBean
implements EntityBean
{
public abstract Set getMemberGangsters();
public abstract void setMemberGangsters(Set gangsters);
} We also can declare the relationship from gangster to organization in the GangsterBean class:
public abstract class GangsterBean
implements EntityBean
{
public abstract Organization getOrganization();
public abstract void setOrganization(Organization org);
}Although each bean declared a CMR field, only one of the two beans in a relationship must have a set of accessors. As with CMP fields, a CMR field is required to have both a getter and a setter method.
The declaration of relationships in the ejb-jar.xml file is complicated and error prone. Although we recommend using a tool like XDoclet to manage the deployment descriptors for CMR fields, it's still important to understand how the descriptor works. The following illustrates the declaration of the organization/gangster relationship:
<ejb-jar>
<relationships>
<ejb-relation>
<ejb-relation-name>Organization-Gangster</ejb-relation-name>
<ejb-relationship-role>
<ejb-relationship-role-name>org-has-gangsters </ejb-relationship-role-name>
<multiplicity>One</multiplicity>
<relationship-role-source>
<ejb-name>OrganizationEJB</ejb-name>
</relationship-role-source>
<cmr-field>
<cmr-field-name>memberGangsters</cmr-field-name>
<cmr-field-type>java.util.Set</cmr-field-type>
</cmr-field>
</ejb-relationship-role>
<ejb-relationship-role>
<ejb-relationship-role-name>
gangster-belongs-to-org
</ejb-relationship-role-name>
<multiplicity>Many</multiplicity>
<cascade-delete/>
<relationship-role-source>
<ejb-name>GangsterEJB</ejb-name>
</relationship-role-source>
<cmr-field>
<cmr-field-name>organization</cmr-field-name>
</cmr-field>
</ejb-relationship-role>
</ejb-relation>
</relationships>
</ejb-jar>As you can see, each relationship is declared with an ejb-relation element within the top level relationships element. The relation is given a name in the ejb-relation-name element. This is important because we will need to refer to the role by name in the jbosscmp-jdbc.xml file. Each ejb-relation contains two ejb-relationship-role elements (one for each side of the relationship). The ejb-relationship-role tags are as follows:
ejb-relationshiprole-name: This optional element is used to identify the role and match the database mapping the jbosscmp-jdbc.xml file. The relationship role names for each side of a relationship must be different.
multiplicity: This indicates the multiplicity of this side of the relationship. The valid values are One or Many. In this example, the multiplicity of the organization is One and the multiplicity of the gangster is Many because the relationship is from one organization to many gangsters. Note, as with all XML elements, this element is case sensitive.
cascade-delete: When this optional element is present, JBoss will delete the child entity when the parent entity is deleted. Cascade deletion is only allowed for a role where the other side of the relationship has a multiplicity of one. The default is to not cascade delete.
relationship-role-source
ejb-name: This required element gives the name of the entity that has the role.
cmr-field
cmr-field-name: This is the name of the CMR field of the entity has one, if it has one.
cmr-field-type: This is the type of the CMR field, if the field is a collection type. It must be java.util.Collection or java.util.Set.
After adding the CMR field abstract accessors and declaring the relationship, the relationship should be functional. The next section discusses the database mapping of the relationship.
Relationships can be mapped using either a foreign key or a separate relation table. One-to-one and one-to-many relationships use the foreign key mapping style by default, and many-to-many relationships use only the relation table mapping style. The mapping of a relationship is declared in the relationships section of the jbosscmp-jdbc.xml descriptor via ejb-relation elements. Relationships are identified by the ejb-relation-name from the ejb-jar.xml file. The jbosscmp-jdbc.xml ejb-relation element content model is shown in Figure 11.7, “The jbosscmp-jdbc.xml ejb-relation element content model”.
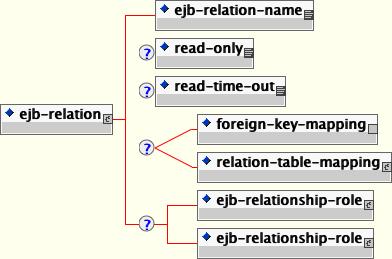
The basic template of the relationship mapping declaration for Organization-Gangster relationship follows:
<jbosscmp-jdbc>
<relationships>
<ejb-relation>
<ejb-relation-name>Organization-Gangster</ejb-relation-name>
<foreign-key-mapping/>
<ejb-relationship-role>
<ejb-relationship-role-name>org-has-gangsters</ejb-relationship-role-name>
<key-fields>
<key-field>
<field-name>name</field-name>
<column-name>organization</column-name>
</key-field>
</key-fields>
</ejb-relationship-role>
<ejb-relationship-role>
<ejb-relationship-role-name>gangster-belongs-to-org</ejb-relationship-role-name>
<key-fields/>
</ejb-relationship-role>
</ejb-relation>
</relationships>
</jbosscmp-jdbc>After the ejb-relation-name of the relationship being mapped is declared, the relationship can be declared as read only using the read-only and read-time-out elements. They have the same semantics as their counterparts in the entity element.
The ejb-relation element must contain either a foreign-key-mapping element or a relation-table-mapping element, which are described in Section 11.5.3.2, “Foreign Key Mapping” and Section 11.5.3.3, “Relation table Mapping”. This element may also contain a pair of ejb-relationship-role elements as described in the following section.
Each of the two ejb-relationship-role elements contains mapping information specific to an entity in the relationship. The content model of the ejb-relationship-role element is shown in Figure 11.8, “The jbosscmp-jdbc ejb-relationship-role element content model” .
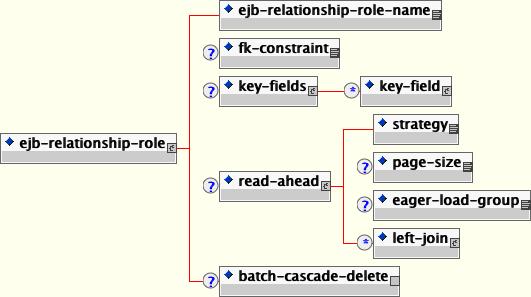
A detailed description of the main elements follows:
ejb-relationship-role-name: This required element gives the name of the role to which this configuration applies. It must match the name of one of the roles declared for this relationship in the ejb-jar.xml file.
fk-constraint: This optional element is a true/false value that indicates whether JBoss should add a foreign key constraint to the tables for this side of the relationship. JBoss will only add generate the constraint if both the primary table and the related table were created by JBoss during deployment.
key-fields: This optional element specifies the mapping of the primary key fields of the current entity, whether it is mapped in the relation table or in the related object. The key-fields element must contain a key-field element for each primary key field of the current entity. The key-fields element can be empty if no foreign key mapping is needed for this side of the relation. An example of this would be the many side of a one-to-many relationship. The details of this element are described below.
read-ahead: This optional element controls the caching of this relationship. This option is discussed in Section 11.8.3.1, “Relationships”.
batch-cascade-delete: This indicates that a cascade delete on this relationship should be performed with a single SQL statement. This requires that the relationship be marked as batch-delete in the ejb-jar.xml.
As noted above, the key-fields element contains a key-field for each primary key field of the current entity. The key-field element uses the same syntax as the cmp-field element of the entity, except that key-field does not support the not-null option. Key fields of a relation-table are automatically not null, because they are the primary key of the table. On the other hand, foreign key fields must be nullable by default. This is because the CMP specification requires an insert into the database after the ejbCreate method and an update to it after to pick up CMR changes made in ejbPostCreate. Since the EJB specification does not allow a relationship to be modified until ejbPostCreate, a foreign key will be initially set to null. There is a similar problem with removal. You can change this insert behavior using the jboss.xml insert-after-ejb-post-create container configuration flag. The following example illustrates the creation of a new bean configuration that uses insert-after-ejb-post-create by default.
<jboss>
<!-- ... -->
<container-configurations>
<container-configuration extends="Standard CMP 2.x EntityBean">
<container-name>INSERT after ejbPostCreate Container</container-name>
<insert-after-ejb-post-create>true</insert-after-ejb-post-create>
</container-configuration>
</container-configurations>
</jboss>An alternate means of working around the non-null foreign key issue is to map the foreign key elements onto non-null CMP fields. In this case you simply populate the foreign key fields in ejbCreate using the associated CMP field setters.
The content model of the key-fields element is Figure 11.9, “The jbosscmp-jdbc key-fields element content model”.
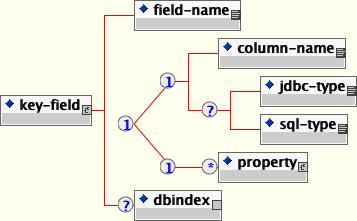
A detailed description of the elements contained in the key-field element follows:
field-name: This required element identifies the field to which this mapping applies. This name must match a primary key field of the current entity.
column-name: Use this element to specify the column name in which this primary key field will be stored. If this is relationship uses foreign-key-mapping, this column will be added to the table for the related entity. If this relationship uses relation-table-mapping, this column is added to the relation-table. This element is not allowed for mapped dependent value class; instead use the property element.
jdbc-type: This is the JDBC type that is used when setting parameters in a JDBC PreparedStatement or loading data from a JDBC ResultSet. The valid types are defined in java.sql.Types.
sql-type: This is the SQL type that is used in create table statements for this field. Valid types are only limited by your database vendor.
property: Use this element for to specify the mapping of a primary key field which is a dependent value class.
dbindex: The presence of this optional field indicates that the server should create an index on the corresponding column in the database, and the index name will be fieldname_index.
Foreign key mapping is the most common mapping style for one-to-one and one-to-many relationships, but is not allowed for many-to many relationships. The foreign key mapping element is simply declared by adding an empty foreign key-mapping element to the ejb-relation element.
As noted in the previous section, with a foreign key mapping the key-fields declared in the ejb-relationship-role are added to the table of the related entity. If the key-fields element is empty, a foreign key will not be created for the entity. In a one-to-many relationship, the many side (Gangster in the example) must have an empty key-fields element, and the one side (Organization in the example) must have a key-fields mapping. In one-to-one relationships, one or both roles can have foreign keys.
The foreign key mapping is not dependent on the direction of the relationship. This means that in a one-to-one unidirectional relationship (only one side has an accessor) one or both roles can still have foreign keys. The complete foreign key mapping for the Organization-Gangster relationship is shown below with the foreign key elements highlighted in bold:
<jbosscmp-jdbc>
<relationships>
<ejb-relation>
<ejb-relation-name>Organization-Gangster</ejb-relation-name>
<foreign-key-mapping/>
<ejb-relationship-role>
<ejb-relationship-role-name>org-has-gangsters</ejb-relationship-role-name>
<key-fields>
<key-field>
<field-name>name</field-name>
<column-name>organization</column-name>
</key-field>
</key-fields>
</ejb-relationship-role>
<ejb-relationship-role>
<ejb-relationship-role-name>gangster-belongs-to-org</ejb-relationship-role-name>
<key-fields/>
</ejb-relationship-role>
</ejb-relation>
</relationships>
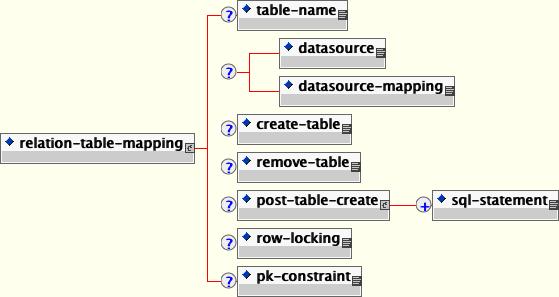
</jbosscmp-jdbc>Relation table mapping is less common for one-to-one and one-to-many relationships, but is the only mapping style allowed for many-to-many relationships. Relation table mapping is defined using the relation-table-mapping element, the content model of which is shown below.
The relation-table-mapping for the Gangster-Job relationship is shown in with table mapping elements highlighted in bold:
Example 11.1. The jbosscmp-jdbc.xml Relation-table Mapping
<jbosscmp-jdbc>
<relationships>
<ejb-relation>
<ejb-relation-name>Gangster-Jobs</ejb-relation-name>
<relation-table-mapping>
<table-name>gangster_job</table-name>
</relation-table-mapping>
<ejb-relationship-role>
<ejb-relationship-role-name>gangster-has-jobs</ejb-relationship-role-name>
<key-fields>
<key-field>
<field-name>gangsterId</field-name>
<column-name>gangster</column-name>
</key-field>
</key-fields>
</ejb-relationship-role>
<ejb-relationship-role>
<ejb-relationship-role-name>job-has-gangsters</ejb-relationship-role-name>
<key-fields>
<key-field>
<field-name>name</field-name>
<column-name>job</column-name>
</key-field>
</key-fields>
</ejb-relationship-role>
</ejb-relation>
</relationships>
</jbosscmp-jdbc>The relation-table-mapping element contains a subset of the options available in the entity element. A detailed description of these elements is reproduced here for convenience:
table-name: This optional element gives the name of the table that will hold data for this relationship. The default table name is based on the entity and cmr-field names.
datasource: This optional element gives the jndi-name used to look up the datasource. All database connections are obtained from the datasource. Having different datasources for entities is not recommended, as it vastly constrains the domain over which finders and ejbSelects can query.
datasourcemapping: This optional element allows one to specify the name of the type-mapping to use.
create-table: This optional element if true indicates JBoss should attempt to create a table for the relationship. When the application is deployed, JBoss checks if a table already exists before creating the table. If a table is found, it is logged, and the table is not created. This option is very useful during the early stages of development when the table structure changes often.
post-table-create: This optional element specifies an arbitrary SQL statement that should be executed immediately after the database table is created. This command is only executed if create-table is true and the table did not previously exist.
remove-table: This optional element if true indicates JBoss should attempt to drop the relation-table when the application is undeployed. This option is very useful during the early stages of development when the table structure changes often.
row-locking: This optional element if true indicates JBoss should lock all rows loaded in a transaction. Most databases implement this by using the SELECT FOR UPDATE syntax when loading the entity, but the actual syntax is determined by the row-locking-template in the datasource-mapping used by this entity.
pk-constraint: This optional element if true indicates JBoss should add a primary key constraint when creating tables.
Entity beans allow for two types of queries: finders and selects. A finder provides queries on an entity bean to clients of the bean. The select method is designed to provide private query statements to an entity implementation. Unlike finders, which are restricted to only return entities of the same type as the home interface on which they are defined, select methods can return any entity type or just one field of the entity. EJB-QL is the query language used to specify finders and select methods in a platform independent way.
The declaration of finders has not changed in CMP 2.0. Finders are still declared in the home interface (local or remote) of the entity. Finders defined on the local home interface do not throw a RemoteException. The following code declares the findBadDudes_ejbql finder on the GangsterHome interface. The ejbql suffix here is not required. It is simply a naming convention used here to differentiate the different types of query specifications we will be looking at.
public interface GangsterHome
extends EJBLocalHome
{
Collection findBadDudes_ejbql(int badness) throws FinderException;
}Select methods are declared in the entity implementation class, and must be public and abstract just like CMP and CMR field abstract accessors and must throw a FinderException. The following code declares an select method:
public abstract class GangsterBean
implements EntityBean
{
public abstract Set ejbSelectBoss_ejbql(String name)
throws FinderException;
}Every select or finder method (except findByPrimaryKey) must have an EJB-QL query defined in the ejb-jar.xml file. The EJB-QL query is declared in a query element, which is contained in the entity element. The following are the declarations for findBadDudes_ejbql and ejbSelectBoss_ejbql queries:
<ejb-jar>
<enterprise-beans>
<entity>
<ejb-name>GangsterEJB</ejb-name>
<!-- ... -->
<query>
<query-method>
<method-name>findBadDudes_ejbql</method-name>
<method-params>
<method-param>int</method-param>
</method-params>
</query-method>
<ejb-ql><![CDATA[
SELECT OBJECT(g)
FROM gangster g
WHERE g.badness > ?1
]]></ejb-ql>
</query>
<query>
<query-method>
<method-name>ejbSelectBoss_ejbql</method-name>
<method-params>
<method-param>java.lang.String</method-param>
</method-params>
</query-method>
<ejb-ql><![CDATA[
SELECT DISTINCT underling.organization.theBoss
FROM gangster underling
WHERE underling.name = ?1 OR underling.nickName = ?1
]]></ejb-ql>
</query>
</entity>
</enterprise-beans>
</ejb-jar>EJB-QL is similar to SQL but has some surprising differences. The following are some important things to note about EJB-QL:
EJB-QL is a typed language, meaning that it only allows comparison of like types (i.e., strings can only be compared with strings).
In an equals comparison a variable (single valued path) must be on the left hand side. Some examples follow:
g.hangout.state = 'CA' Legal 'CA' = g.shippingAddress.state NOT Legal 'CA' = 'CA' NOT Legal (r.amountPaid * .01) > 300 NOT Legal r.amountPaid > (300 / .01) Legal
Parameters use a base 1 index like java.sql.PreparedStatement.
Parameters are only allowed on the right hand side of a comparison. For example:
gangster.hangout.state = ?1 Legal ?1 = gangster.hangout.state NOT Legal
The EJB-QL query can be overridden in the jbosscmp-jdbc.xml file. The finder or select is still required to have an EJB-QL declaration, but the ejb-ql element can be left empty. Currently the SQL can be overridden with JBossQL, DynamicQL, DeclaredSQL or a BMP style custom ejbFind method. All EJB-QL overrides are non-standard extensions to the EJB specification, so use of these extensions will limit portability of your application. All of the EJB-QL overrides, except for BMP custom finders, are declared using a query element in the jbosscmp-jdbc.xml file. Tthe content model is shown in Figure 11.11, “The jbosscmp-jdbc query element content model”.
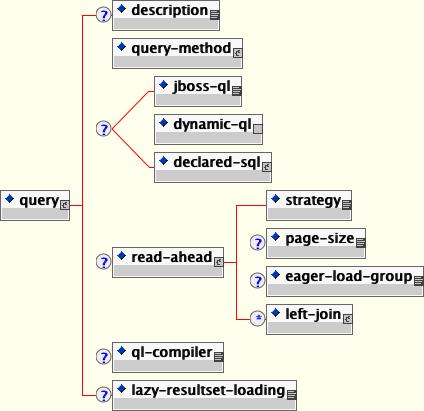
description: An optional description for the query.
query-method: This required element specifies the query method that being configured. This must match a query-method declared for this entity in the ejb-jar.xml file.
jboss-ql: This is a JBossQL query to use in place of the EJB-QL query. JBossQL is discussed in Section 11.6.4, “JBossQL”.
dynamic-ql: This indicated that the method is a dynamic query method and not an EJB-QL query. Dynamic queries are discussed in Section 11.6.5, “DynamicQL”.
declared-sql: This query uses declared SQL in place of the EJB-QL query. Declared SQL is discussed in Section 11.6.6, “DeclaredSQL”.
read-ahead: This optional element allows one to optimize the loading of additional fields for use with the entities referenced by the query. This is discussed in detail in Section 11.7, “Optimized Loading”.
JBossQL is a superset of EJB-QL that is designed to address some of the inadequacies of EJB-QL. In addition to a more flexible syntax, new functions, key words, and clauses have been added to JBossQL. At the time of this writing, JBossQL includes support for an ORDER BY, OFFSET and LIMIT clauses, parameters in the IN and LIKE operators, the COUNT, MAX, MIN, AVG, SUM, UCASE and LCASE functions. Queries can also include functions in the SELECT clause for select methods.
JBossQL is declared in the jbosscmp-jdbc.xml file with a jboss-ql element containing the JBossQL query. The following example provides an example JBossQL declaration.
<jbosscmp-jdbc>
<enterprise-beans>
<entity>
<ejb-name>GangsterEJB</ejb-name>
<query>
<query-method>
<method-name>findBadDudes_jbossql</method-name>
<method-params>
<method-param>int</method-param>
</method-params>
</query-method>
<jboss-ql><![CDATA[
SELECT OBJECT(g)
FROM gangster g
WHERE g.badness > ?1
ORDER BY g.badness DESC
]]></jboss-ql>
</query>
</entity>
</enterprise-beans>
</jbosscmp-jdbc>The corresponding generated SQL is straightforward.
SELECT t0_g.id
FROM gangster t0_g
WHERE t0_g.badness > ?
ORDER BY t0_g.badness DESCAnother capability of JBossQL is the ability to retrieve finder results in blocks using the LIMIT and OFFSET functions. For example, to iterate through the large number of jobs performed, the following findManyJobs_jbossql finder may be defined.
<jbosscmp-jdbc>
<enterprise-beans>
<entity>
<ejb-name>GangsterEJB</ejb-name>
<query>
<query-method>
<method-name>findManyJobs_jbossql</method-name>
<method-params>
<method-param>int</method-param>
</method-params>
<method-params>
<method-param>int</method-param>
</method-params>
</query-method>
<jboss-ql><![CDATA[
SELECT OBJECT(j)
FROM jobs j
OFFSET ?1 LIMIT ?2
]]></jboss-ql>
</query>
</entity>
</enterprise-beans>
</jbosscmp-jdbc>DynamicQL allows the runtime generation and execution of JBossQL queries. A DynamicQL query method is an abstract method that takes a JBossQL query and the query arguments as parameters. JBoss compiles the JBossQL and executes the generated SQL. The following generates a JBossQL query that selects all the gangsters that have a hangout in any state in the states set:
public abstract class GangsterBean
implements EntityBean
{
public Set ejbHomeSelectInStates(Set states)
throws FinderException
{
// generate JBossQL query
StringBuffer jbossQl = new StringBuffer();
jbossQl.append("SELECT OBJECT(g) ");
jbossQl.append("FROM gangster g ");
jbossQl.append("WHERE g.hangout.state IN (");
for (int i = 0; i < states.size(); i++) {
if (i > 0) {
jbossQl.append(", ");
}
jbossQl.append("?").append(i+1);
}
jbossQl.append(") ORDER BY g.name");
// pack arguments into an Object[]
Object[] args = states.toArray(new Object[states.size()]);
// call dynamic-ql query
return ejbSelectGeneric(jbossQl.toString(), args);
}
}The DynamicQL select method may have any valid select method name, but the method must always take a string and an object array as parameters. DynamicQL is declared in the jbosscmp-jdbc.xml file with an empty dynamic-ql element. The following is the declaration for ejbSelectGeneric.
<jbosscmp-jdbc>
<enterprise-beans>
<entity>
<ejb-name>GangsterEJB</ejb-name>
<query>
<query-method>
<method-name>ejbSelectGeneric</method-name>
<method-params>
<method-param>java.lang.String</method-param>
<method-param>java.lang.Object[]</method-param>
</method-params>
</query-method>
<dynamic-ql/>
</query>
</entity>
</enterprise-beans>
</jbosscmp-jdbc>DeclaredSQL is based on the legacy JAWS CMP 1.1 engine finder declaration, but has been updated for CMP 2.0. Commonly this declaration is used to limit a query with a WHERE clause that cannot be represented in q EJB-QL or JBossQL. The content model for the declared-sql element is given in Figure 11.12, “The jbosscmp-jdbc declared-sql element content model.>”.
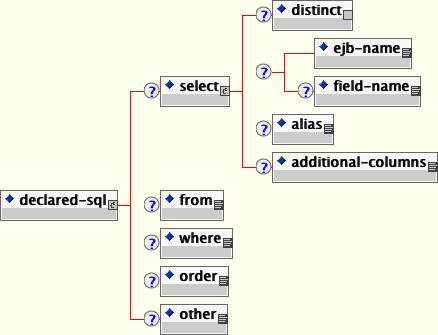
select: The select element specifies what is to be selected and consists of the following elements:
distinct: If this empty element is present, JBoss will add the DISTINCT keyword to the generated SELECT clause. The default is to use DISTINCT if method returns a java.util.Set
ejb-name: This is the ejb-name of the entity that will be selected. This is only required if the query is for a select method.
field-name: This is the name of the CMP field that will be selected from the specified entity. The default is to select entire entity.
alias: This specifies the alias that will be used for the main select table. The default is to use the ejb-name.
additional-columns: Declares other columns to be selected to satisfy ordering by arbitrary columns with finders or to facilitate aggregate functions in selects.
from: The from element declares additional SQL to append to the generated FROM clause.
where: The where element declares the WHERE clause for the query.
order: The order element declares the ORDER clause for the query.
other: The other element declares additional SQL that is appended to the end of the query.
The following is an example DeclaredSQL declaration.
<jbosscmp-jdbc>
<enterprise-beans>
<entity>
<ejb-name>GangsterEJB</ejb-name>
<query>
<query-method>
<method-name>findBadDudes_declaredsql</method-name>
<method-params>
<method-param>int</method-param>
</method-params>
</query-method>
<declared-sql>
<where><![CDATA[ badness > {0} ]]></where>
<order><![CDATA[ badness DESC ]]></order>
</declared-sql>
</query>
</entity>
</enterprise-beans>
</jbosscmp-jdbc>The generated SQL would be:
SELECT id FROM gangster WHERE badness > ? ORDER BY badness DESC
As you can see, JBoss generates the SELECT and FROM clauses necessary to select the primary key for this entity. If desired an additional FROM clause can be specified that is appended to the end of the automatically generated FROM clause. The following is example DeclaredSQL declaration with an additional FROM clause.
<jbosscmp-jdbc>
<enterprise-beans>
<entity>
<ejb-name>GangsterEJB</ejb-name>
<query>
<query-method>
<method-name>ejbSelectBoss_declaredsql</method-name>
<method-params>
<method-param>java.lang.String</method-param>
</method-params>
</query-method>
<declared-sql>
<select>
<distinct/>
<ejb-name>GangsterEJB</ejb-name>
<alias>boss</alias>
</select>
<from><![CDATA[, gangster g, organization o]]></from>
<where><![CDATA[
(LCASE(g.name) = {0} OR LCASE(g.nick_name) = {0}) AND
g.organization = o.name AND o.the_boss = boss.id
]]></where>
</declared-sql>
</query>
</entity>
</enterprise-beans>
</jbosscmp-jdbc>The generated SQL would be:
SELECT DISTINCT boss.id
FROM gangster boss, gangster g, organization o
WHERE (LCASE(g.name) = ? OR LCASE(g.nick_name) = ?) AND
g.organization = o.name AND o.the_boss = boss.idNotice that the FROM clause starts with a comma. This is because the container appends the declared FROM clause to the end of the generated FROM clause. It is also possible for the FROM clause to start with a SQL JOIN statement. Since this is a select method, it must have a select element to declare the entity that will be selected. Note that an alias is also declared for the query. If an alias is not declared, the table-name is used as the alias, resulting in a SELECT clause with the table_name.field_name style column declarations. Not all database vendors support the that syntax, so the declaration of an alias is preferred. The optional empty distinct element causes the SELECT clause to use the SELECT DISTINCT declaration. The DeclaredSQL declaration can also be used in select methods to select a CMP field.
Now we well see an example which overrides a select to return all of the zip codes an Organization operates in.
<jbosscmp-jdbc>
<enterprise-beans>
<entity>
<ejb-name>OrganizationEJB</ejb-name>
<query>
<query-method>
<method-name>ejbSelectOperatingZipCodes_declaredsql</method-name>
<method-params>
<method-param>java.lang.String</method-param>
</method-params>
</query-method>
<declared-sql>
<select>
<distinct/>
<ejb-name>LocationEJB</ejb-name>
<field-name>zipCode</field-name>
<alias>hangout</alias>
</select>
<from><![CDATA[ , organization o, gangster g ]]></from>
<where><![CDATA[
LCASE(o.name) = {0} AND o.name = g.organization AND
g.hangout = hangout.id
]]></where>
<order><![CDATA[ hangout.zip ]]></order>
</declared-sql>
</query>
</entity>
</enterprise-beans>
</jbosscmp-jdbc>The corresponding SQL would be:
SELECT DISTINCT hangout.zip
FROM location hangout, organization o, gangster g
WHERE LCASE(o.name) = ? AND o.name = g.organization AND g.hangout = hangout.id
ORDER BY hangout.zipDeclaredSQL uses a completely new parameter handling system, which supports entity and DVC parameters. Parameters are enclosed in curly brackets and use a zero-based index, which is different from the one-based EJB-QL parameters. There are three categories of parameters: simple, DVC, and entity.
simple: A simple parameter can be of any type except for a known (mapped) DVC or an entity. A simple parameter only contains the argument number, such as {0}. When a simple parameter is set, the JDBC type used to set the parameter is determined by the datasourcemapping for the entity. An unknown DVC is serialized and then set as a parameter. Note that most databases do not support the use of a BLOB value in a WHERE clause.
DVC: A DVC parameter can be any known (mapped) DVC. A DVC parameter must be dereferenced down to a simple property (one that is not another DVC). For example, if we had a CVS property of type ContactInfo, valid parameter declarations would be {0.email} and {0.cell.areaCode} but not {0.cell}. The JDBC type used to set a parameter is based on the class type of the property and the datasourcemapping of the entity. The JDBC type used to set the parameter is the JDBC type that is declared for that property in the dependent-value-class element.
entity: An entity parameter can be any entity in the application. An entity parameter must be dereferenced down to a simple primary key field or simple property of a DVC primary key field. For example, if we had a parameter of type Gangster, a valid parameter declaration would be {0.gangsterId}. If we had some entity with a primary key field named info of type ContactInfo, a valid parameter declaration would be {0.info.cell.areaCode}. Only fields that are members of the primary key of the entity can be dereferenced (this restriction may be removed in later versions). The JDBC type used to set the parameter is the JDBC type that is declared for that field in the entity declaration.
The default query compiler doesn't fully support EJB-QL 2.1 or the SQL92 standard. If you need either of these functions, you can replace the query compiler. The default compiler is specified in standardjbosscmp-jdbc.xml.
<defaults>
...
<ql-compiler>org.jboss.ejb.plugins.cmp.jdbc.JDBCEJBQLCompiler</ql-compiler>
...
</defaults>To use the SQL92 compiler, simply specify the SQL92 compiler in ql-compiler element.
<defaults>
...
<ql-compiler>org.jboss.ejb.plugins.cmp.jdbc.EJBQLToSQL92Compiler</ql-compiler>
...
</defaults>This changes the query compiler for all beans in the entire system. You can also specify the ql-compiler for each element in jbosscmp-jdbc.xml. Here is an example using one of our earlier queries.
<query>
<query-method>
<method-name>findBadDudes_ejbql</method-name>
<method-params>
lt;method-param>int</method-param>
</method-params>
</query-method>
<ejb-ql><![CDATA[
SELECT OBJECT(g)
FROM gangster g
WHERE g.badness > ?1]]>
</ejb-ql>
<ql-compiler>org.jboss.ejb.plugins.cmp.jdbc.EJBQLToSQL92Compiler</ql-compiler>
</query>One important limitation of SQL92 query compiler is that it always selects all the fields of an entity regardless the read-ahead strategy in use. For example, if a query is configured with the on-load read-ahead strategy, the first query will include all the fields, not just primary key fields but only the primary key fields will be read from the ResultSet. Then, on load, other fields will be actually loaded into the read-ahead cache. The on-find read-ahead with the default load group * works as expected.
JBoss also supports bean managed persistence custom finders. If a custom finder method matches a finder declared in the home or local home interface, JBoss will always call the custom finder over any other implementation declared in the ejb-jar.xml or jbosscmp-jdbc.xml files. The following simple example finds the entities by a collection of primary keys:
public abstract class GangsterBean
implements EntityBean
{
public Collection ejbFindByPrimaryKeys(Collection keys)
{
return keys;
}
} This is a very useful finder because it quickly coverts primary keys into real Entity objects without contacting the database. One drawback is that it can create an Entity object with a primary key that does not exist in the database. If any method is invoked on the bad Entity, a NoSuchEntityException will be thrown. Another drawback is that the resulting entity bean violates the EJB specification in that it implements a finder, and the JBoss EJB verifier will fail the deployment of such an entity unless the StrictVerifier attribute is set to false.
The goal of optimized loading is to load the smallest amount of data required to complete a transaction in the fewest number of queries. The tuning of JBoss depends on a detailed knowledge of the loading process. This section describes the internals of the JBoss loading process and its configuration. Tuning of the loading process really requires a holistic understanding of the loading system, so this chapter may have to be read more than once.
The easiest way to investigate the loading process is to look at a usage scenario. The most common scenario is to locate a collection of entities and iterate over the results performing some operation. The following example generates an html table containing all of the gangsters:
public String createGangsterHtmlTable_none()
throws FinderException
{
StringBuffer table = new StringBuffer();
table.append("<table>");
Collection gangsters = gangsterHome.findAll_none();
for (Iterator iter = gangsters.iterator(); iter.hasNext();) {
Gangster gangster = (Gangster) iter.next();
table.append("<tr>");
table.append("<td>").append(gangster.getName());
table.append("</td>");
table.append("<td>").append(gangster.getNickName());
table.append("</td>");
table.append("<td>").append(gangster.getBadness());
table.append("</td>");
table.append("</tr>");
}
return table.toString();
}Assume this code is called within a single transaction and all optimized loading has been disabled. At the findAll_none call, JBoss will execute the following query:
SELECT t0_g.id
FROM gangster t0_g
ORDER BY t0_g.id ASCThen as each of the eight gangster in the sample database is accessed, JBoss will execute the following eight queries:
SELECT name, nick_name, badness, hangout, organization FROM gangster WHERE (id=0) SELECT name, nick_name, badness, hangout, organization FROM gangster WHERE (id=1) SELECT name, nick_name, badness, hangout, organization FROM gangster WHERE (id=2) SELECT name, nick_name, badness, hangout, organization FROM gangster WHERE (id=3) SELECT name, nick_name, badness, hangout, organization FROM gangster WHERE (id=4) SELECT name, nick_name, badness, hangout, organization FROM gangster WHERE (id=5) SELECT name, nick_name, badness, hangout, organization FROM gangster WHERE (id=6) SELECT name, nick_name, badness, hangout, organization FROM gangster WHERE (id=7)
There are two problems with this scenario. First, an excessive number of queries are executed because JBoss executes one query for the findAll and one query to access each element found. The reason for this behavior has to do with the handling of query results inside the JBoss container. Although it appears that the actual entity beans selected are returned when a query is executed, JBoss really only returns the primary keys of the matching entities, and does not load the entity until a method is invoked on it. This is known as the n+1 problem and is addressed with the read-ahead strategies described in the following sections.
Second, the values of unused fields are loaded needlessly. JBoss loads the hangout and organization fields, which are never accessed. (we have disabled the complex contactInfo field for the sake of clarity)
The following table shows the execution of the queries:
The configuration and optimization of the loading system begins with the declaration of named load groups in the entity. A load group contains the names of CMP fields and CMR Fields that have a foreign key (e.g., Gangster in the Organization-Gangster example) that will be loaded in a single operation. An example configuration is shown below:
<jbosscmp-jdbc>
<enterprise-beans>
<entity>
<ejb-name>GangsterEJB</ejb-name>
<!-- ... -->
<load-groups>
<load-group>
<load-group-name>basic</load-group-name>
<field-name>name</field-name>
<field-name>nickName</field-name>
<field-name>badness</field-name>
</load-group>
<load-group>
<load-group-name>contact info</load-group-name>
<field-name>nickName</field-name>
<field-name>contactInfo</field-name>
<field-name>hangout</field-name>
</load-group>
</load-groups>
</entity>
</enterprise-beans>
</jbosscmp-jdbc>In this example, two load groups are declared: basic and contact info. Note that the load groups do not need to be mutually exclusive. For example, both of the load groups contain the nickName field. In addition to the declared load groups, JBoss automatically adds a group named * (the star group) that contains every CMP field and CMR field with a foreign key in the entity.
Optimized loading in JBoss is called read-ahead. This refers to the technique of reading the row for an entity being loaded, as well as the next several rows; hence the term read-ahead. JBoss implements two main strategies (on-find and on-load) to optimize the loading problem identified in the previous section. The extra data loaded during read-ahead is not immediately associated with an entity object in memory, as entities are not materialized in JBoss until actually accessed. Instead, it is stored in the preload cache where it remains until it is loaded into an entity or the end of the transaction occurs. The following sections describe the read-ahead strategies.
The on-find strategy reads additional columns when the query is invoked. If the query is on-find optimized, JBoss will execute the following query when the query is executed.
SELECT t0_g.id, t0_g.name, t0_g.nick_name, t0_g.badness
FROM gangster t0_g
ORDER BY t0_g.id ASCAll of the required data would be in the preload cache, so no additional queries would need to be executed while iterating through the query results. This strategy is effective for queries that return a small amount of data, but it becomes very inefficient when trying to load a large result set into memory. The following table shows the execution of this query:
Table 11.2. on-find Optimized Query Execution
| id | name | nick_name | badness | hangout | organization |
|---|---|---|---|---|---|
| 0 | Yojimbo | Bodyguard | 7 | 0 | Yakuza |
| 1 | Takeshi | Master | 10 | 1 | Yakuza |
| 2 | Yuriko | Four finger | 4 | 2 | Yakuza |
| 3 | Chow | Killer | 9 | 3 | Triads |
| 4 | Shogi | Lightning | 8 | 4 | Triads |
| 5 | Valentino | Pizza-Face | 4 | 5 | Mafia |
| 6 | Toni | Toothless | 2 | 6 | Mafia |
| 7 | Corleone | Godfather | 6 | 7 | Mafia |
The read-ahead strategy and load-group for a query is defined in the query element. If a read-ahead strategy is not declared in the query element, the strategy declared in the entity element or defaults element is used. The on-find configuration follows:
<jbosscmp-jdbc>
<enterprise-beans>
<entity>
<ejb-name>GangsterEJB</ejb-name>
<!--...-->
<query>
<query-method>
<method-name>findAll_onfind</method-name>
<method-params/>
</query-method>
<jboss-ql><![CDATA[
SELECT OBJECT(g)
FROM gangster g
ORDER BY g.gangsterId
]]></jboss-ql>
<read-ahead>
<strategy>on-find</strategy>
<page-size>4</page-size>
<eager-load-group>basic</eager-load-group>
</read-ahead>
</query>
</entity>
</enterprise-beans>
</jbosscmp-jdbc> One problem with the on-find strategy is that it must load additional data for every entity selected. Commonly in web applications only a fixed number of results are rendered on a page. Since the preloaded data is only valid for the length of the transaction, and a transaction is limited to a single web HTTP hit, most of the preloaded data is not used. The on-load strategy discussed in the next section does not suffer from this problem.
Left join read ahead is an enhanced on-find read-ahead strategy. It allows you to preload in one SQL query not only fields from the base instance but also related instances which can be reached from the base instance by CMR navigation. There are no limitation for the depth of CMR navigations. There are also no limitations for cardinality of CMR fields used in navigation and relationship type mapping, i.e. both foreign key and relation-table mapping styles are supported. Let's look at some examples. Entity and relationship declarations can be found below.
Suppose we have an entity D. A typical SQL query generated for the findByPrimaryKey would look like this:
SELECT t0_D.id, t0_D.name FROM D t0_D WHERE t0_D.id=?
Suppose that while executing findByPrimaryKey we also want to preload two collection-valued CMR fields bs and cs.
<query>
<query-method>
<method-name>findByPrimaryKey</method-name>
<method-params>
<method-param>java.lang.Long</method-param>
</method-params>
</query-method>
<jboss-ql><![CDATA[SELECT OBJECT(o) FROM D AS o WHERE o.id = ?1]]></jboss-ql>
<read-ahead>
<strategy>on-find</strategy>
<page-size>4</page-size>
<eager-load-group>basic</eager-load-group>
<left-join cmr-field="bs" eager-load-group="basic"/>
<left-join cmr-field="cs" eager-load-group="basic"/>
</read-ahead>
</query>The left-join declares the relations to be eager loaded. The generated SQL would look like this:
SELECT t0_D.id, t0_D.name,
t1_D_bs.id, t1_D_bs.name,
t2_D_cs.id, t2_D_cs.name
FROM D t0_D
LEFT OUTER JOIN B t1_D_bs ON t0_D.id=t1_D_bs.D_FK
LEFT OUTER JOIN C t2_D_cs ON t0_D.id=t2_D_cs.D_FK
WHERE t0_D.id=?For the D with the specific id we preload all its related B's and C's and can access those instance loading them from the read ahead cache, not from the database.
In the same way, we could optimize the findAll method on D selects all the D's. A normal findAll query would look like this:
SELECT DISTINCT t0_o.id, t0_o.name FROM D t0_o ORDER BY t0_o.id DESC
To preload the relations, we simply need to add the left-join elements to the query.
<query>
<query-method>
<method-name>findAll</method-name>
</query-method>
<jboss-ql><![CDATA[SELECT DISTINCT OBJECT(o) FROM D AS o ORDER BY o.id DESC]]></jboss-ql>
<read-ahead>
<strategy>on-find</strategy>
<page-size>4</page-size>
<eager-load-group>basic</eager-load-group>
<left-join cmr-field="bs" eager-load-group="basic"/>
<left-join cmr-field="cs" eager-load-group="basic"/>
</read-ahead>
</query>And here is the generated SQL:
SELECT DISTINCT t0_o.id, t0_o.name,
t1_o_bs.id, t1_o_bs.name,
t2_o_cs.id, t2_o_cs.name
FROM D t0_o
LEFT OUTER JOIN B t1_o_bs ON t0_o.id=t1_o_bs.D_FK
LEFT OUTER JOIN C t2_o_cs ON t0_o.id=t2_o_cs.D_FK
ORDER BY t0_o.id DESCNow the simple findAll query now preloads the related B and C objects for each D object.
Now let's look at a more complex configuration. Here we want to preload instance A along with several relations.
its parent (self-relation) reached from A with CMR field parent
the B reached from A with CMR field b, and the related C reached from B with CMR field c
B reached from A but this time with CMR field b2 and related to it C reached from B with CMR field c.
For reference, the standard query would be:
SELECT t0_o.id, t0_o.name FROM A t0_o ORDER BY t0_o.id DESC FOR UPDATE
The following metadata describes our preloading plan.
<query>
<query-method>
<method-name>findAll</method-name>
</query-method>
<jboss-ql><![CDATA[SELECT OBJECT(o) FROM A AS o ORDER BY o.id DESC]]></jboss-ql>
<read-ahead>
<strategy>on-find</strategy>
<page-size>4</page-size>
<eager-load-group>basic</eager-load-group>
<left-join cmr-field="parent" eager-load-group="basic"/>
<left-join cmr-field="b" eager-load-group="basic">
<left-join cmr-field="c" eager-load-group="basic"/>
</left-join>
<left-join cmr-field="b2" eager-load-group="basic">
<left-join cmr-field="c" eager-load-group="basic"/>
</left-join>
</read-ahead>
</query>The SQL query generated would be:
SELECT t0_o.id, t0_o.name,
t1_o_parent.id, t1_o_parent.name,
t2_o_b.id, t2_o_b.name,
t3_o_b_c.id, t3_o_b_c.name,
t4_o_b2.id, t4_o_b2.name,
t5_o_b2_c.id, t5_o_b2_c.name
FROM A t0_o
LEFT OUTER JOIN A t1_o_parent ON t0_o.PARENT=t1_o_parent.id
LEFT OUTER JOIN B t2_o_b ON t0_o.B_FK=t2_o_b.id
LEFT OUTER JOIN C t3_o_b_c ON t2_o_b.C_FK=t3_o_b_c.id
LEFT OUTER JOIN B t4_o_b2 ON t0_o.B2_FK=t4_o_b2.id
LEFT OUTER JOIN C t5_o_b2_c ON t4_o_b2.C_FK=t5_o_b2_c.id
ORDER BY t0_o.id DESC FOR UPDATEWith this configuration, you can navigate CMRs from any found instance of A without an additional database load.
Here is another example of self-relation. Suppose, we want to write a method that would preload an instance, its parent, grand-parent and its grand-grand-parent in one query. To do this, we would used nested left-join declaration.
<query>
<query-method>
<method-name>findMeParentGrandParent</method-name>
<method-params>
<method-param>java.lang.Long</method-param>
</method-params>
</query-method>
<jboss-ql><![CDATA[SELECT OBJECT(o) FROM A AS o WHERE o.id = ?1]]></jboss-ql>
<read-ahead>
<strategy>on-find</strategy>
<page-size>4</page-size>
<eager-load-group>*</eager-load-group>
<left-join cmr-field="parent" eager-load-group="basic">
<left-join cmr-field="parent" eager-load-group="basic">
<left-join cmr-field="parent" eager-load-group="basic"/>
</left-join>
</left-join>
</read-ahead>
</query>The generated SQL would be:
SELECT t0_o.id, t0_o.name, t0_o.secondName, t0_o.B_FK, t0_o.B2_FK, t0_o.PARENT,
t1_o_parent.id, t1_o_parent.name,
t2_o_parent_parent.id, t2_o_parent_parent.name,
t3_o_parent_parent_parent.id, t3_o_parent_parent_parent.name
FROM A t0_o
LEFT OUTER JOIN A t1_o_parent ON t0_o.PARENT=t1_o_parent.id
LEFT OUTER JOIN A t2_o_parent_parent ON t1_o_parent.PARENT=t2_o_parent_parent.id
LEFT OUTER JOIN A t3_o_parent_parent_parent
ON t2_o_parent_parent.PARENT=t3_o_parent_parent_parent.id
WHERE (t0_o.id = ?) FOR UPDATENote, if we remove left-join metadata we will have only
SELECT t0_o.id, t0_o.name, t0_o.secondName, t0_o.B2_FK, t0_o.PARENT FOR UPDATE
The on-load strategy block-loads additional data for several entities when an entity is loaded, starting with the requested entity and the next several entities in the order they were selected. This strategy is based on the theory that the results of a find or select will be accessed in forward order. When a query is executed, JBoss stores the order of the entities found in the list cache. Later, when one of the entities is loaded, JBoss uses this list to determine the block of entities to load. The number of lists stored in the cache is specified with the list-cachemax element of the entity. This strategy is also used when faulting in data not loaded in the on-find strategy.
As with the on-find strategy, on-load is declared in the read-ahead element. The on-load configuration for this example is shown below.
<jbosscmp-jdbc>
<enterprise-beans>
<entity>
<ejb-name>GangsterEJB</ejb-name>
<!-- ... -->
<query>
<query-method>
<method-name>findAll_onload</method-name>
<method-params/>
</query-method>
<jboss-ql><![CDATA[
SELECT OBJECT(g)
FROM gangster g
ORDER BY g.gangsterId
]]></jboss-ql>
<read-ahead>
<strategy>on-load</strategy>
<page-size>4</page-size>
<eager-load-group>basic</eager-load-group>
</read-ahead>
</query>
</entity>
</enterprise-beans>
</jbosscmp-jdbc>With this strategy, the query for the finder method in remains unchanged.
SELECT t0_g.id
FROM gangster t0_g
ORDER BY t0_g.id ASC However, the data will be loaded differently as we iterate through the result set. For a page size of four, JBoss will only need to execute the following two queries to load the name, nickName and badness fields for the entities:
SELECT id, name, nick_name, badness
FROM gangster
WHERE (id=0) OR (id=1) OR (id=2) OR (id=3)
SELECT id, name, nick_name, badness
FROM gangster
WHERE (id=4) OR (id=5) OR (id=6) OR (id=7)The following table shows the execution of these queries:
Table 11.3. on-load Optimized Query Execution
| id | name | nick_name | badness | hangout | organization |
|---|---|---|---|---|---|
| 0 | Yojimbo | Bodyguard | 7 | 0 | Yakuza |
| 1 | Takeshi | Master | 10 | 1 | Yakuza |
| 2 | Yuriko | Four finger | 4 | 2 | Yakuza |
| 3 | Chow | Killer | 9 | 3 | Triads |
| 4 | Shogi | Lightning | 8 | 4 | Triads |
| 5 | Valentino | Pizza-Face | 4 | 5 | Mafia |
| 6 | Toni | Toothless | 2 | 6 | Mafia |
| 7 | Corleone | Godfather | 6 | 7 | Mafia |
The none strategy is really an anti-strategy. This strategy causes the system to fall back to the default lazy-load code, and specifically does not read-ahead any data or remember the order of the found entities. This results in the queries and performance shown at the beginning of this chapter. The none strategy is declared with a read-ahead element. If the read-ahead element contains a page-size element or eager-load-group, it is ignored. The none strategy is declared the following example.
<jbosscmp-jdbc>
<enterprise-beans>
<entity>
<ejb-name>GangsterEJB</ejb-name>
<!-- ... -->
<query>
<query-method>
<method-name>findAll_none</method-name>
<method-params/>
</query-method>
<jboss-ql><![CDATA[
SELECT OBJECT(g)
FROM gangster g
ORDER BY g.gangsterId
]]></jboss-ql>
<read-ahead>
<strategy>none</strategy>
</read-ahead>
</query>
</entity>
</enterprise-beans>
</jbosscmp-jdbc>In the previous section several steps use the phrase "when the entity is loaded." This was intentionally left vague because the commit option specified for the entity and the current state of the transaction determine when an entity is loaded. The following section describes the commit options and the loading processes.
Central to the loading process are the commit options, which control when the data for an entity expires. JBoss supports four commit options A, B, C and D. The first three are described in the Enterprise JavaBeans Specification, but the last one is specific to JBoss. A detailed description of each commit option follows:
A: JBoss assumes it is the sole user of the database; therefore, JBoss can cache the current value of an entity between transactions, which can result is substantial performance gains. As a result of this assumption, no data managed by JBoss can be changed outside of JBoss. For example, changing data in another program or with the use of direct JDBC (even within JBoss) will result in an inconsistent database state.
B: JBoss assumes that there is more than one user of the database but keeps the context information about entities between transactions. This context information is used for optimizing loading of the entity. This is the default commit option.
C: JBoss discards all entity context information at the end of the transaction.
D: This is a JBoss specific commit option. This option is similar to commit option A, except that the data only remains valid for a specified amount of time.
The commit option is declared in the jboss.xml file. For a detailed description of this file see Chapter 5, EJBs on JBoss. The following example changes the commit option to A for all entity beans in the application:
When an entity is loaded, JBoss must determine the fields that need to be loaded. By default, JBoss will use the eager-load-group of the last query that selected this entity. If the entity has not been selected in a query, or the last query used the none read-ahead strategy, JBoss will use the default eager-load-group declared for the entity. In the following example configuration, the basic load group is set as the default eager-load-group for the gangster entity bean:
<jbosscmp-jdbc>
<enterprise-beans>
<entity>
<ejb-name>GangsterEJB</ejb-name>
<!-- ... -->
<load-groups>
<load-group>
<load-group-name>most</load-group-name>
<field-name>name</field-name>
<field-name>nickName</field-name>
<field-name>badness</field-name>
<field-name>hangout</field-name>
<field-name>organization</field-name>
</load-group>
</load-groups>
<eager-load-group>most</eager-load-group>
</entity>
</enterprise-beans>
</jbosscmp-jdbc>The eager loading process is initiated the first time a method is called on an entity in a transaction. A detailed description of the load process follows:
If the entity context is still valid, no loading is necessary, and therefore the loading process is done. The entity context will be valid when using commit option A, or when using commit option D, and the data has not timed out.
Any residual data in the entity context is flushed. This assures that old data does not bleed into the new load.
The primary key value is injected back into the primary key fields. The primary key object is actually independent of the fields and needs to be reloaded after the flush in step 2.
All data in the preload cache for this entity is loaded into the fields.
JBoss determines the additional fields that still need to be loaded. Normally the fields to load are determined by the eager-load group of the entity, but can be overridden if the entity was located using a query or CMR field with an on-find or on-load read ahead strategy. If all of the fields have already been loaded, the load process skips to step 7.
A query is executed to select the necessary column. If this entity is using the on-load strategy, a page of data is loaded as described in Section 11.7.3.2, “on-load”. The data for the current entity is stored in the context and the data for the other entities is stored in the preload cache.
The ejbLoad method of the entity is called.
Lazy loading is the other half of eager loading. If a field is not eager loaded, it must be lazy loaded. When an access to an unloaded field of a bean is made, JBoss loads the field and all the fields of any lazy-load-group the field belong to. JBoss performs a set join and then removes any field that is already loaded. An example configuration is shown below.
<jbosscmp-jdbc>
<enterprise-beans>
<entity>
<ejb-name>GangsterEJB</ejb-name>
<!-- ... -->
<load-groups>
<load-group>
<load-group-name>basic</load-group-name>
<field-name>name</field-name>
<field-name>nickName</field-name>
<field-name>badness</field-name>
</load-group>
<load-group>
<load-group-name>contact info</load-group-name>
<field-name>nickName</field-name>
<field-name>contactInfo</field-name>
<field-name>hangout</field-name>
</load-group>
</load-groups>
<!-- ... -->
<lazy-load-groups>
<load-group-name>basic</load-group-name>
<load-group-name>contact info</load-group-name>
</lazy-load-groups>
</entity>
</enterprise-beans>
</jbosscmp-jdbc>When the bean provider calls getName() with this configuration, JBoss loads name, nickName and badness, assuming they are not already loaded. When the bean provider calls getNickName(), the name, nickName, badness, contactInfo, and hangout are loaded. A detailed description of the lazy loading process follows:
All data in the preload cache for this entity is loaded into the fields.
If the field value was loaded by the preload cache the lazy load process is finished.
JBoss finds all of the lazy load groups that contain this field, performs a set join on the groups, and removes any field that has already been loaded.
A query is executed to select the necessary columns. As in the basic load process, JBoss may load a block of entities. The data for the current entity is stored in the context and the data for the other entities is stored in the preload cache.
Relationships are a special case in lazy loading because a CMR field is both a field and query. As a field it can be on-load block loaded, meaning the value of the currently sought entity and the values of the CMR field for the next several entities are loaded. As a query, the field values of the related entity can be preloaded using on-find.
Again, the easiest way to investigate the loading is to look at a usage scenario. In this example, an HTML table is generated containing each gangster and their hangout. The example code follows:
Example 11.3. Relationship Lazy Loading Example Code
public String createGangsterHangoutHtmlTable()
throws FinderException
{
StringBuffer table = new StringBuffer();
table.append("<table>");
Collection gangsters = gangsterHome.findAll_onfind();
for (Iterator iter = gangsters.iterator(); iter.hasNext(); ) {
Gangster gangster = (Gangster)iter.next();
Location hangout = gangster.getHangout();
table.append("<tr>");
table.append("<td>").append(gangster.getName());
table.append("</td>");
table.append("<td>").append(gangster.getNickName());
table.append("</td>");
table.append("<td>").append(gangster.getBadness());
table.append("</td>");
table.append("<td>").append(hangout.getCity());
table.append("</td>");
table.append("<td>").append(hangout.getState());
table.append("</td>");
table.append("<td>").append(hangout.getZipCode());
table.append("</td>");
table.append("</tr>");
}
table.append("</table>");return table.toString();
}For this example, the configuration of the gangster's findAll_onfind query is unchanged from the on-find section. The configuration of the Location entity and Gangster-Hangout relationship follows:
Example 11.4. The jbosscmp-jdbc.xml Relationship Lazy Loading Configuration
<jbosscmp-jdbc>
<enterprise-beans>
<entity>
<ejb-name>LocationEJB</ejb-name>
<load-groups>
<load-group>
<load-group-name>quick info</load-group-name>
<field-name>city</field-name>
<field-name>state</field-name>
<field-name>zipCode</field-name>
</load-group>
</load-groups>
<eager-load-group/>
</entity>
</enterprise-beans>
<relationships>
<ejb-relation>
<ejb-relation-name>Gangster-Hangout</ejb-relation-name>
<foreign-key-mapping/>
<ejb-relationship-role>
<ejb-relationship-role-name>
gangster-has-a-hangout
</ejb-relationship-role-name>
<key-fields/>
<read-ahead>
<strategy>on-find</strategy>
<page-size>4</page-size>
<eager-load-group>quick info</eager-load-group>
</read-ahead>
</ejb-relationship-role>
<ejb-relationship-role>
<ejb-relationship-role-name>
hangout-for-a-gangster
</ejb-relationship-role-name>
<key-fields>
<key-field>
<field-name>locationID</field-name>
<column-name>hangout</column-name>
</key-field>
</key-filaelds>
</ejb-relationship-role>
</ejb-relation>
</relationships>
</jbosscmp-jdbc>JBoss will execute the following query for the finder:
SELECT t0_g.id, t0_g.name, t0_g.nick_name, t0_g.badness
FROM gangster t0_g
ORDER BY t0_g.id ASCThen when the hangout is accessed, JBoss executes the following two queries to load the city, state, and zip fields of the hangout:
SELECT gangster.id, gangster.hangout,
location.city, location.st, location.zip
FROM gangster, location
WHERE (gangster.hangout=location.id) AND
((gangster.id=0) OR (gangster.id=1) OR
(gangster.id=2) OR (gangster.id=3))
SELECT gangster.id, gangster.hangout,
location.city, location.st, location.zip
FROM gangster, location
WHERE (gangster.hangout=location.id) AND
((gangster.id=4) OR (gangster.id=5) OR
(gangster.id=6) OR (gangster.id=7))The following table shows the execution of the queries:
Table 11.4. on-find Optimized Relationship Query Execution
| id | name | nick_name | badness | hangout | id | city | st | zip |
|---|---|---|---|---|---|---|---|---|
| 0 | Yojimbo | Bodyguard | 7 | 0 | 0 | San Fran | CA | 94108 |
| 1 | Takeshi | Master | 10 | 1 | 1 | San Fran | CA | 94133 |
| 2 | Yuriko | Four finger | 4 | 2 | 2 | San Fran | CA | 94133 |
| 3 | Chow | Killer | 9 | 3 | 3 | San Fran | CA | 94133 |
| 4 | Shogi | Lightning | 8 | 4 | 4 | San Fran | CA | 94133 |
| 5 | Valentino | Pizza-Face | 4 | 5 | 5 | New York | NY | 10017 |
| 6 | Toni | Toothless | 2 | 6 | 6 | Chicago | IL | 60661 |
| 7 | Corleone | Godfather | 6 | 7 | 7 | Las Vegas | NV | 89109 |
By default, when a multi-object finder or select method is executed the JDBC result set is read to the end immediately. The client receives a collection of EJBLocalObject or CMP field values which it can then iterate through. For big result sets this approach is not efficient. In some cases it is better to delay reading the next row in the result set until the client tries to read the corresponding value from the collection. You can get this behavior for a query using the lazy-resultset-loading element.
<query>
<query-method>
<method-name>findAll</method-name>
</query-method>
<jboss-ql><![CDATA[select object(o) from A o]]></jboss-ql>
<lazy-resultset-loading>true</lazy-resultset-loading>
</query>The are some issues you should be aware of when using lazy result set loading. Special care should be taken when working with a Collection associated with a lazily loaded result set. The first call to iterator() returns a special Iterator that reads from the ResultSet. Until this Iterator has been exhausted, subsequent calls to iterator() or calls to the add() method will result in an exception. The remove() and size() methods work as would be expected.
All of the examples presented in this chapter have been defined to run in a transaction. Transaction granularity is a dominating factor in optimized loading because transactions define the lifetime of preloaded data. If the transaction completes, commits, or rolls back, the data in the preload cache is lost. This can result in a severe negative performance impact.
The performance impact of running without a transaction will be demonstrated with an example that uses an on-find optimized query that selects the first four gangsters (to keep the result set small), and it is executed without a wrapper transaction. The example code follows:
public String createGangsterHtmlTable_no_tx() throws FinderException
{
StringBuffer table = new StringBuffer();
table.append("<table>");
Collection gangsters = gangsterHome.findFour();
for(Iterator iter = gangsters.iterator(); iter.hasNext(); ) {
Gangster gangster = (Gangster)iter.next();
table.append("<tr>");
table.append("<td>").append(gangster.getName());
table.append("</td>");
table.append("<td>").append(gangster.getNickName());
table.append("</td>");
table.append("<td>").append(gangster.getBadness());
table.append("</td>");
table.append("</tr>");
}
table.append("</table>");
return table.toString();
} The finder results in the following query being executed:
SELECT t0_g.id, t0_g.name, t0_g.nick_name, t0_g.badness FROM gangster t0_g WHERE t0_g.id < 4 ORDER BY t0_g.id ASC
Normally this would be the only query executed, but since this code is not running in a transaction, all of the preloaded data is thrown away as soon as finder returns. Then when the CMP field is accessed JBoss executes the following four queries (one for each loop):
SELECT id, name, nick_name, badness FROM gangster WHERE (id=0) OR (id=1) OR (id=2) OR (id=3) SELECT id, name, nick_name, badness FROM gangster WHERE (id=1) OR (id=2) OR (id=3) SELECT id, name, nick_name, badness FROM gangster WHERE (id=2) OR (id=3) SELECT name, nick_name, badness FROM gangster WHERE (id=3)
It's actually worse than this. JBoss executes each of these queries three times; once for each CMP field that is accessed. This is because the preloaded values are discarded between the CMP field accessor calls.
The following figure shows the execution of the queries:
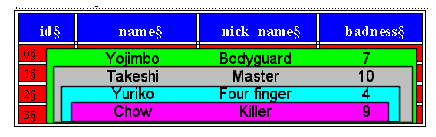
This performance is much worse than read ahead none because of the amount of data loaded from the database. The number of rows loaded is determined by the following equation:
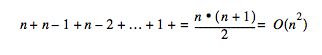
This all happens because the transaction in the example is bounded by a single call on the entity. This brings up the important question "How do I run my code in a transaction?" The answer depends on where the code runs. If it runs in an EJB (session, entity, or message driven), the method must be marked with the Required or RequiresNew trans-attribute in the assembly-descriptor. If the code is not running in an EJB, a user transaction is necessary. The following code wraps a call to the declared method with a user transaction:
public String createGangsterHtmlTable_with_tx()
throws FinderException
{
UserTransaction tx = null;
try {
InitialContext ctx = new InitialContext();
tx = (UserTransaction) ctx.lookup("UserTransaction");
tx.begin();
String table = createGangsterHtmlTable_no_tx();
if (tx.getStatus() == Status.STATUS_ACTIVE) {
tx.commit();
}
return table;
} catch (Exception e) {
try {
if (tx != null) tx.rollback();
} catch (SystemException unused) {
// eat the exception we are exceptioning out anyway
}
if (e instanceof FinderException) {
throw (FinderException) e;
}
if (e instanceof RuntimeException) {
throw (RuntimeException) e;
}
throw new EJBException(e);
}
}JBoss has supports for optimistic locking of entity beans. Optimistic locking allows multiple instances of the same entity bean to be active simultaneously. Consistency is enforced based on the optimistic locking policy choice. The optimistic locking policy choice defines the set of fields that are used in the commit time write of modified data to the database. The optimistic consistency check asserts that the values of the chosen set of fields has the same values in the database as existed when the current transaction was started. This is done using a select for UPDATE WHERE ... statement that contains the value assertions.
You specify the optimistic locking policy choice using an optimistic-locking element in the jbosscmp-jdbc.xml descriptor. The content model of the optimistic-locking element is shown below and the description of the elements follows.
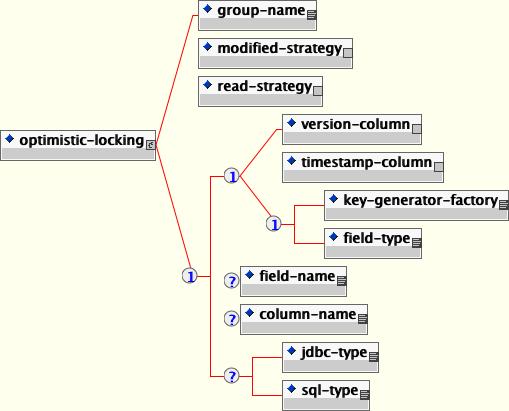
group-name: This element specifies that optimistic locking is based on the fields of a load-group. This value of this element must match one of the entity's load-group-name. The fields in this group will be used for optimistic locking.
modified-strategy: This element specifies that optimistic locking is based on the modified fields. This strategy implies that the fields that were modified during transaction will be used for optimistic locking.
read-strategy: This element specifies that optimistic locking is based on the fields read. This strategy implies that the fields that were read/changed in the transaction will be used for optimistic locking.
version-column: This element specifies that optimistic locking is based on a version column strategy. Specifying this element will add an additional version field of type java.lang.Long to the entity bean for optimistic locking. Each update of the entity will increase the value of this field. The field-name element allows for the specification of the name of the CMP field while the column-name element allows for the specification of the corresponding table column.
timestamp-column: This element specifies that optimistic locking is based on a timestamp column strategy. Specifying this element will add an additional version field of type java.util.Date to the entity bean for optimistic locking. Each update of the entity will set the value of this field to the current time. The field-name element allows for the specification of the name of the CMP field while the column-name element allows for the specification of the corresponding table column.
key-generator-factory: This element specifies that optimistic locking is based on key generation. The value of the element is the JNDI name of a org.jboss.ejb.plugins.keygenerator.KeyGeneratorFactory implementation. Specifying this element will add an additional version field to the entity bean for optimistic locking. The type of the field must be specified via the field-type element. Each update of the entity will update the key field by obtaining a new value from the key generator. The field-name element allows for the specification of the name of the CMP field while the column-name element allows for the specification of the corresponding table column.
A sample jbosscmp-jdbc.xml descriptor illustrating all of the optimistic locking strategies is given below.
<!DOCTYPE jbosscmp-jdbc PUBLIC
"-//JBoss//DTD JBOSSCMP-JDBC 3.2//EN"
"http://www.jboss.org/j2ee/dtd/jbosscmp-jdbc_3_2.dtd">
<jbosscmp-jdbc>
<defaults>
<datasource>java:/DefaultDS</datasource>
<datasource-mapping>Hypersonic SQL</datasource-mapping>
</defaults>
<enterprise-beans>
<entity>
<ejb-name>EntityGroupLocking</ejb-name>
<create-table>true</create-table>
<remove-table>true</remove-table>
<table-name>entitygrouplocking</table-name>
<cmp-field>
<field-name>dateField</field-name>
</cmp-field>
<cmp-field>
<field-name>integerField</field-name>
</cmp-field>
<cmp-field>
<field-name>stringField</field-name>
</cmp-field>
<load-groups>
<load-group>
<load-group-name>string</load-group-name>
<field-name>stringField</field-name>
</load-group>
<load-group>
<load-group-name>all</load-group-name>
<field-name>stringField</field-name>
<field-name>dateField</field-name>
</load-group>
</load-groups>
<optimistic-locking>
<group-name>string</group-name>
</optimistic-locking>
</entity>
<entity>
<ejb-name>EntityModifiedLocking</ejb-name>
<create-table>true</create-table>
<remove-table>true</remove-table>
<table-name>entitymodifiedlocking</table-name>
<cmp-field>
<field-name>dateField</field-name>
</cmp-field>
<cmp-field>
<field-name>integerField</field-name>
</cmp-field>
<cmp-field>
<field-name>stringField</field-name>
</cmp-field>
<optimistic-locking>
<modified-strategy/>
</optimistic-locking>
</entity>
<entity>
<ejb-name>EntityReadLocking</ejb-name>
<create-table>true</create-table>
<remove-table>true</remove-table>
<table-name>entityreadlocking</table-name>
<cmp-field>
<field-name>dateField</field-name>
</cmp-field>
<cmp-field>
<field-name>integerField</field-name>
</cmp-field>
<cmp-field>
<field-name>stringField</field-name>
</cmp-field>
<optimistic-locking>
<read-strategy/>
</optimistic-locking>
</entity>
<entity>
<ejb-name>EntityVersionLocking</ejb-name>
<create-table>true</create-table>
<remove-table>true</remove-table>
<table-name>entityversionlocking</table-name>
<cmp-field>
<field-name>dateField</field-name>
</cmp-field>
<cmp-field>
<field-name>integerField</field-name>
</cmp-field>
<cmp-field>
<field-name>stringField</field-name>
</cmp-field>
<optimistic-locking>
<version-column/>
<field-name>versionField</field-name>
<column-name>ol_version</column-name>
<jdbc-type>INTEGER</jdbc-type>
<sql-type>INTEGER(5)</sql-type>
</optimistic-locking>
</entity>
<entity>
<ejb-name>EntityTimestampLocking</ejb-name>
<create-table>true</create-table>
<remove-table>true</remove-table>
<table-name>entitytimestamplocking</table-name>
<cmp-field>
<field-name>dateField</field-name>
</cmp-field>
<cmp-field>
<field-name>integerField</field-name>
</cmp-field>
<cmp-field>
<field-name>stringField</field-name>
</cmp-field>
<optimistic-locking>
<timestamp-column/>
<field-name>versionField</field-name>
<column-name>ol_timestamp</column-name>
<jdbc-type>TIMESTAMP</jdbc-type>
<sql-type>DATETIME</sql-type>
</optimistic-locking>
</entity>
<entity>
<ejb-name>EntityKeyGeneratorLocking</ejb-name>
<create-table>true</create-table>
<remove-table>true</remove-table>
<table-name>entitykeygenlocking</table-name>
<cmp-field>
<field-name>dateField</field-name>
</cmp-field>
<cmp-field>
<field-name>integerField</field-name>
</cmp-field>
<cmp-field>
<field-name>stringField</field-name>
</cmp-field>
<optimistic-locking>
<key-generator-factory>UUIDKeyGeneratorFactory</key-generator-factory>
<field-type>java.lang.String</field-type>
<field-name>uuidField</field-name>
<column-name>ol_uuid</column-name>
<jdbc-type>VARCHAR</jdbc-type>
<sql-type>VARCHAR(32)</sql-type>
</optimistic-locking>
</entity>
</enterprise-beans>
</jbosscmp-jdbc>Support for primary key generation outside of the entity bean is available through custom implementations of the entity creation command objects used to insert entities into a persistent store. The list of available commands is specified in entity-commands element of the jbosscmp-jdbc.xml descriptor. The default entity-command may be specified in the jbosscmp-jdbc.xml in defaults element. Each entity element can override the entity-command in defaults by specifying its own entity-command. The content model of the entity-commands and child elements is given below.

Each entity-command element specifies an entity generation implementation. The name attribute specifies a name that allows the command defined in an entity-commands section to be referenced in the defaults and entity elements. The class attribute specifies the implementation of the org.jboss.ejb.plugins.cmp.jdbc. JDBCCreateEntityCommand that supports the key generation. Database vendor specific commands typically subclass the org.jboss.ejb.plugins.cmp.jdbc. JDBCIdentityColumnCreateCommand if the database generates the primary key as a side effect of doing an insert, or the org.jboss.ejb.plugins.cmp.jdbc.JDBCInsertPKCreateCommand if the command must insert the generated key.
The optional attribute element(s) allows for the specification of arbitrary name/value property pairs that will be available to the entity command implementation class. The attribute element has a required name attribute that specifies the name property, and the attribute element content is the value of the property. The attribute values are accessible through the org.jboss.ejb.plugins.cmp.jdbc.metadata.JDBCEntityCommandMetaData.getAttribute(String) method.
The following are the current entity-command definitions found in the standardjbosscmp-jdbc.xml descriptor:
default: (org.jboss.ejb.plugins.cmp.jdbc.JDBCCreateEntityCommand) The JDBCCreateEntityCommand is the default entity creation as it is the entity-command referenced in the standardjbosscmp-jdbc.xml defaults element. This entity-command executes an INSERT INTO query using the assigned primary key value.
no-select-before-insert: (org.jboss.ejb.plugins.cmp.jdbc.JDBCCreateEntityCommand) This is a variation on default that skips select before insert by specifying an attribute name="SQLExceptionProcessor" that points to the jboss.jdbc:service=SQLExceptionProcessor service. The SQLExceptionProcessor service provides a boolean isDuplicateKey(SQLException e) operation that allows a for determination of any unique constraint violation.
pk-sql (org.jboss.ejb.plugins.cmp.jdbc.JDBCPkSqlCreateCommand) The JDBCPkSqlCreateCommand executes an INSERT INTO query statement provided by the pk-sql attribute to obtain the next primary key value. Its primary target usage are databases with sequence support.
mysql-get-generated-keys: (org.jboss.ejb.plugins.cmp.jdbc.mysql.JDBCMySQLCreateCommand) The JDBCMySQLCreateCommand executes an INSERT INTO query using the getGeneratedKeys method from MySQL native java.sql.Statement interface implementation to fetch the generated key.
oracle-sequence: (org.jboss.ejb.plugins.cmp.jdbc.keygen.JDBCOracleCreateCommand) The JDBCOracleCreateCommand is a create command for use with Oracle that uses a sequence in conjunction with a RETURNING clause to generate keys in a single statement. It has a required sequence element that specifies the name of the sequence column.
hsqldb-fetch-key: (org.jboss.ejb.plugins.cmp.jdbc.hsqldb.JDBCHsqldbCreateCommand) The JDBCHsqldbCreateCommand executes an INSERT INTO query after executing a CALL IDENTITY() statement to fetch the generated key.
sybase-fetch-key: (org.jboss.ejb.plugins.cmp.jdbc.sybase.JDBCSybaseCreateCommand) The JDBCSybaseCreateCommand executes an INSERT INTO query after executing a SELECT @@IDENTITY statement to fetch the generated key.
mssql-fetch-key: (org.jboss.ejb.plugins.cmp.jdbc.keygen.JDBCSQLServerCreateCommand) The JDBCSQLServerCreateCommand for Microsoft SQL Server that uses the value from an IDENTITY columns. By default uses SELECT SCOPE_IDENTITY() to reduce the impact of triggers; can be overridden with pk-sql attribute e.g. for V7.
informix-serial: (org.jboss.ejb.plugins.cmp.jdbc.informix.JDBCInformixCreateCommand) The JDBCInformixCreateCommand executes an INSERT INTO query after using the getSerial method from Informix native java.sql.Statement interface implementation to fetch the generated key.
postgresql-fetch-seq: (org.jboss.ejb.plugins.cmp.jdbc.keygen.JDBCPostgreSQLCreateCommand) The JDBCPostgreSQLCreateCommand for PostgreSQL that fetches the current value of the sequence. The optional sequence attribute can be used to change the name of the sequence, with the default being table_pkColumn_seq.
key-generator: (org.jboss.ejb.plugins.cmp.jdbc.JDBCKeyGeneratorCreateCommand) The JDBCKeyGeneratorCreateCommand executes an INSERT INTO query after obtaining a value for the primary key from the key generator referenced by the key-generator-factory. The key-generator-factory attribute must provide the name of a JNDI binding of the org.jboss.ejb.plugins.keygenerator.KeyGeneratorFactory implementation.
get-generated-keys: (org.jboss.ejb.plugins.cmp.jdbc.jdbc3.JDBCGetGeneratedKeysCreateCommand) The JDBCGetGeneratedKeysCreateCommand executes an INSERT INTO query using a statement built using the JDBC3 prepareStatement(String, Statement.RETURN_GENERATED_KEYS) that has the capability to retrieve the auto-generated key. The generated key is obtained by calling the PreparedStatement.getGeneratedKeys method. Since this requires JDBC3 support it is only available in JDK1.4.1+ with a supporting JDBC driver.
An example configuration using the hsqldb-fetch-key entity-command with the generated key mapped to a known primary key cmp-field is shown below.
<jbosscmp-jdbc>
<enterprise-beans>
<entity>
<ejb-name>LocationEJB</ejb-name>
<pk-constraint>false</pk-constraint>
<table-name>location</table-name>
<cmp-field>
<field-name>locationID</field-name>
<column-name>id</column-name>
<auto-increment/>
</cmp-field>
<!-- ... -->
<entity-command name="hsqldb-fetch-key"/>
</entity>
</enterprise-beans>
</jbosscmp-jdbc>An alternate example using an unknown primary key without an explicit cmp-field is shown below.
<jbosscmp-jdbc>
<enterprise-beans>
<entity>
<ejb-name>LocationEJB</ejb-name>
<pk-constraint>false</pk-constraint>
<table-name>location</table-name>
<unknown-pk>
<unknown-pk-class>java.lang.Integer</unknown-pk-class>
<field-name>locationID</field-name>
<column-name>id</column-name>
<jdbc-type>INTEGER</jdbc-type>
<sql-type>INTEGER</sql-type>
<auto-increment/>
</unknown-pk>
<!--...-->
<entity-command name="hsqldb-fetch-key"/>
</entity>
</enterprise-beans>
</jbosscmp-jdbc>JBoss global defaults are defined in the standardjbosscmp-jdbc.xml file of the server/<server-name>/conf/ directory. Each application can override the global defaults in the jbosscmp-jdbc.xml file. The default options are contained in a defaults element of the configuration file, and the content model is shown below.
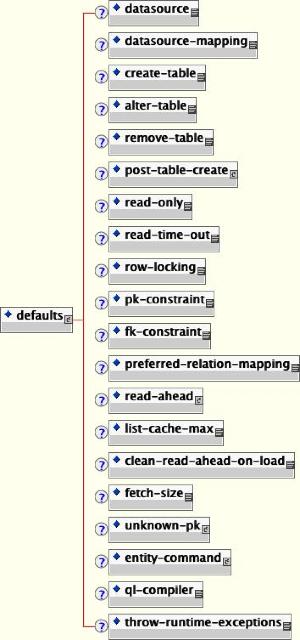
An example of the defaults section follows:
<jbosscmp-jdbc>
<defaults>
<datasource>java:/DefaultDS</datasource>
<datasource-mapping>Hypersonic SQL</datasource-mapping>
<create-table>true</create-table>
<remove-table>false</remove-table>
<read-only>false</read-only>
<read-time-out>300000</read-time-out>
<pk-constraint>true</pk-constraint>
<fk-constraint>false</fk-constraint>
<row-locking>false</row-locking>
<preferred-relation-mapping>foreign-key</preferred-relation-mapping>
<read-ahead>
<strategy>on-load</strategy>
<page-size>1000</page-size>
<eager-load-group>*</eager-load-group>
</read-ahead>
<list-cache-max>1000</list-cache-max>
</defaults>
</jbosscmp-jdbc>Each option can apply to entities, relationships, or both, and can be overridden in the specific entity or relationship. A detailed description of each option follows:
datasource: This optional element is the jndi-name used to look up the datasource. All database connections used by an entity or relation-table are obtained from the datasource. Having different datasources for entities is not recommended, as it vastly constrains the domain over which finders and ejbSelects can query.
datasource-mapping: This optional element specifies the name of the type-mapping, which determines how Java types are mapped to SQL types, and how EJB-QL functions are mapped to database specific functions. Type mappings are discussed in Section 11.13.3, “Mapping”.
create-table: This optional element when true, specifies that JBoss should attempt to create a table for the entity. When the application is deployed, JBoss checks if a table already exists before creating the table. If a table is found, it is logged, and the table is not created. This option is very useful during the early stages of development when the table structure changes often. The default is false.
alter-table: If create-table is used to automatically create the schema, alter-table can be used to keep the schema current with changes to the entity bean. Alter table will perform the following specific tasks:
new fields will be created
fields which are no longer used will be removed
string fields which are shorter than the declared length will have their length increased to the declared length. (not supported by all databases)
remove-table: This optional element when true, JBoss will attempt to drop the table for each entity and each relation table mapped relationship. When the application is undeployed, JBoss will attempt to drop the table. This option is very useful during the early stages of development when the table structure changes often. The default is false.
read-only: This optional element when true specifies that the bean provider will not be allowed to change the value of any fields. A field that is read-only will not be stored in, or inserted into, the database. If a primary key field is read-only, the create method will throw a CreateException. If a set accessor is called on a read-only field, it throws an EJBException. Read only fields are useful for fields that are filled in by database triggers, such as last update. The read-only option can be overridden on a per field basis. The default is false.
read-time-out: This optional element is the amount of time in milliseconds that a read on a read only field is valid. A value of 0 means that the value is always reloaded at the start of a transaction, and a value of -1 means that the value never times out. This option can also be overridden on a per CMP field basis. If read-only is false, this value is ignored. The default is -1.
row-locking: This optional element if true specifies that JBoss will lock all rows loaded in a transaction. Most databases implement this by using the SELECT FOR UPDATE syntax when loading the entity, but the actual syntax is determined by the row-locking-template in the datasource-mapping used by this entity. The default is false.
pk-constraint: This optional element if true specifies that JBoss will add a primary key constraint when creating tables. The default is true.
preferred-relation-mapping: This optional element specifies the preferred mapping style for relationships. The preferred-relation-mapping element must be either foreign-key or relation-table.
read-ahead: This optional element controls caching of query results and CMR fields for the entity. This option is discussed in Section 11.7.3, “Read-ahead”.
list-cache-max: This optional element specifies the number of read-lists that can be tracked by this entity. This option is discussed in Section 11.7.3.2, “on-load”. The default is 1000.
clean-read-ahead-on-load: When an entity is loaded from the read ahead cache, JBoss can remove the data used from the read ahead cache. The default is false.
fetch-size: This optional element specifies the number of entities to read in one round-trip to the underlying datastore. The default is 0.
unknown-pk: This optional element allows one to define the default mapping of an unknown primary key type of java.lang.Object maps to the persistent store.
entity-command: This optional element allows one to define the default command for entity creation. This is described in detail in Section 11.11, “Entity Commands and Primary Key Generation”.
ql-compiler: This optional elements allows a replacement query compiler to be specified. Alternate query compilers were discussed in Section 11.6.7, “EJBQL 2.1 and SQL92 queries”.
throw-runtime-exceptions: This attribute, if set to true, indicates that an error in connecting to the database should be seen in the application as runtime EJBException rather than as a checked exception.
JBoss includes predefined type-mappings for many databases including: Cloudscape, DB2, DB2/400, Hypersonic SQL, InformixDB, InterBase, MS SQLSERVER, MS SQLSERVER2000, mySQL, Oracle7, Oracle8, Oracle9i, PointBase, PostgreSQL, PostgreSQL 7.2, SapDB, SOLID, and Sybase. If you do not like the supplied mapping, or a mapping is not supplied for your database, you will have to define a new mapping. If you find an error in one of the supplied mappings, or if you create a new mapping for a new database, please consider posting a patch at the JBoss project page on SourceForge.
Customization of a database is done through the type-mapping section of the jbosscmp-jdbc.xml descriptor. The content model for the type-mapping element is given in Figure 11.17, “The jbosscmp-jdbc type-mapping element content model.”.

The elements are:
name: This required element provides the name identifying the database customization. It is used to refer to the mapping by the datasource-mapping elements found in defaults and entity.
row-locking-template: This required element gives the PreparedStatement template used to create a row lock on the selected rows. The template must support three arguments:
the select clause
the from clause. The order of the tables is currently not guaranteed
the where clause
If row locking is not supported in select statement this element should be empty. The most common form of row locking is select for update as in: SELECT ?1 FROM ?2 WHERE ?3 FOR UPDATE.
pk-constraint-template: This required element gives the PreparedStatement template used to create a primary key constraint in the create table statement. The template must support two arguments
Primary key constraint name; which is always pk_{table-name}
Comma separated list of primary key column names
If a primary key constraint clause is not supported in a create table statement this element should be empty. The most common form of a primary key constraint is: CONSTRAINT ?1 PRIMARY KEY (?2)
fk-constraint-template: This is the template used to create a foreign key constraint in separate statement. The template must support five arguments:
Table name
Foreign key constraint name; which is always fk_{table-name}_{cmr-field-name}
Comma separated list of foreign key column names
References table name
Comma separated list of the referenced primary key column names
If the datasource does not support foreign key constraints this element should be empty. The most common form of a foreign key constraint is: ALTER TABLE ?1 ADD CONSTRAINT ?2 FOREIGN KEY (?3) REFERENCES ?4 (?5).
auto-increment-template: This declares the SQL template for specifying auto increment columns.
add-column-template: When alter-table is true, this SQL template specifies the syntax for adding a column to an existing table. The default value is ALTER TABLE ?1 ADD ?2 ?3. The parameters are:
the table name
the column name
the column type
alter-column-template: When alter-table is true, this SQL template specifies the syntax for dropping a column to from an existing table. The default value is ALTER TABLE ?1 ALTER ?2 TYPE ?3. The parameters are:
the table name
the column name
the column type
drop-column-template: When alter-table is true, this SQL template specifies the syntax for dropping a column to from an existing table. The default value is ALTER TABLE ?1 DROP ?2. The parameters are:
the table name
the column name
alias-header-prefix: This required element gives the prefix used in creating the alias header. An alias header is prepended to a generated table alias by the EJB-QL compiler to prevent name collisions. The alias header is constructed as follows: alias-header-prefix + int_counter + alias-header-suffix. An example alias header would be t0_ for an alias-header-prefix of "t" and an alias-header-suffix of "_".
alias-header-suffix: This required element gives the suffix portion of the generated alias header.
alias-max-length: This required element gives the maximum allowed length for the generated alias header.
subquery-supported: This required element specifies if this type-mapping subqueries as either true or false. Some EJB-QL operators are mapped to exists subqueries. If subquery-supported is false, the EJB-QL compiler will use a left join and is null.
true-mapping: This required element defines true identity in EJB-QL queries. Examples include TRUE, 1, and (1=1).
false-mapping: This required element defines false identity in EJB-QL queries. Examples include FALSE, 0, and (1=0).
function-mapping: This optional element specifies one or more the mappings from an EJB-QL function to an SQL implementation. See Section 11.13.2, “Function Mapping” for the details.
mapping: This required element specifies the mappings from a Java type to the corresponding JDBC and SQL type. See Section 11.13.3, “Mapping” for the details.
The function-mapping element model is show below.
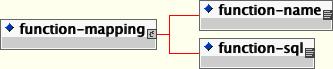
The allowed child elements are:
function-name: This required element gives the EJB-QL function name, e.g., concat, substring.
function-sql: This required element gives the SQL for the function as appropriate for the underlying database. Examples for a concat function include: (?1 || ?2), concat(?1, ?2), (?1 + ?2).
A type-mapping is simply a set of mappings between Java class types and database types. A set of type mappings is defined by a set of mapping elements, the content model for which is shown in Figure 11.19, “The jbosscmp-jdbc mapping element content model.”.
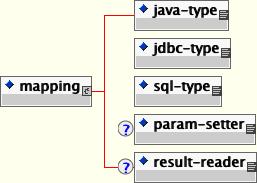
If JBoss cannot find a mapping for a type, it will serialize the object and use the java.lang.Object mapping. The following describes the three child elements of the mapping element:
java-type: This required element gives the fully qualified name of the Java class to be mapped. If the class is a primitive wrapper class such as java.lang.Short, the mapping also applies to the primitive type.
jdbc-type: This required element gives the JDBC type that is used when setting parameters in a JDBC PreparedStatement or loading data from a JDBC ResultSet. The valid types are defined in java.sql.Types.
sql-type: This required element gives the SQL type that is used in create table statements. Valid types are only limited by your database vendor.
param-setter: This optional element specifies the fully qualified name of the JDBCParameterSetter implementation for this mapping.
result-reader: This option element specifies the fully qualified name of the JDBCResultSetReader implementation for this mapping.
An example mapping element for a short in Oracle9i is shown below.
<jbosscmp-jdbc>
<type-mappings>
<type-mapping>
<name>Oracle9i</name>
<!--...-->
<mapping>
<java-type>java.lang.Short</java-type>
<jdbc-type>NUMERIC</jdbc-type>
<sql-type>NUMBER(5)</sql-type>
</mapping>
</type-mapping>
</type-mappings>
</jbosscmp-jdbc>User type mappings allow one to map from JDBC column types to custom CMP fields types by specifying an instance of org.jboss.ejb.plugins.cmp.jdbc.Mapper interface, the definition of which is shown below.
public interface Mapper
{
/**
* This method is called when CMP field is stored.
* @param fieldValue - CMP field value
* @return column value.
*/
Object toColumnValue(Object fieldValue);
/**
* This method is called when CMP field is loaded.
* @param columnValue - loaded column value.
* @return CMP field value.
*/
Object toFieldValue(Object columnValue);
}A prototypical use case is the mapping of an integer type to its type-safe Java enumeration instance. The content model of the user-type-mappings element consists of one or more user-type-mapping elements, the content model of which is shown in Figure 11.20, “The user-type-mapping content model >”.
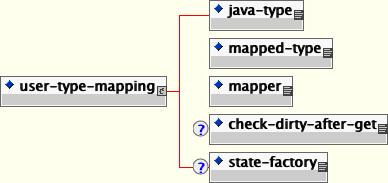
java-type: the fully qualified name of the CMP field type in the mapping.
mapped-type: the fully qualified name of the database type in the mapping.
mapper: the fully qualified name of the Mapper interface implementation that handles the conversion between the java-type and mapped-type.